The monitoring console module collects a multitude of metrics from all nodes and accumulates the data on the DAS. The data is visualised by the monitoring console web-application.
The metrics include server metrics as well as metrics defined in user applications using MicroProfile Metrics and metrics derived from MicroProfile Health.
| Please be aware that following details reflect the current state of a evolving product that are likely to change in the future. |
Enabling the GUI
By default the monitoring console GUI is automatically enabled for the production domain.
Links can be found on the Common Tasks home page in section Monitoring or on the Monitoring Data page.
For domain1 the GUI is not enabled by default and the set-monitoring-console-configuration is used to enable it on demand.
To enable the monitoring console GUI run the following asadmin command:
asadmin> set-monitoring-console-configuration --enabled=true
The console is now available at http://localhost:8080/monitoring-console/ . Like the admin GUI the monitoring console only runs on the DAS.
To stop the monitoring console GUI run:
asadmin> set-monitoring-console-configuration --enabled=false
Stopping the GUI does not disable the data collection. This is a background process that is controlled separately as described in the next section.
| The monitoring console feature is only contained in Payara Server distribution. |
Enabling Data Collection
The collection of monitoring data gets enabled and disabled in connection with the general configuration: Monitoring ⇒ Monitoring Service ⇒ Enabled
To remove only the monitoring data collection from the server without disabling the monitoring service itself delete the monitoring-console-core.jar from the /glassfish/modules folder of your installation(s) and restart the server.
|
Graphical User Interface
After enabling the monitoring console open the home page at /monitoring-console/ (usually on port 8080).
The console comes with a set of preconfigured pages each focussing on different aspects of the server.
The console will let you know that some metrics are only available when the monitoring configuration of certain server parts is set to HIGH.
|
Pages
The monitoring console is organized in fully customisable pages. A page is a collection of widgets arranged in columns. Usually pages are focussed on visualising metrics of a specific area of the server, like HTTP or request tracing. The monitoring console has preconfigured pages as a starting point that can be changed and extended by the user. New custom pages can be created.
Switching Pages
To switch page use the drop-down menu at the top centre of the page.

Since version 5.20.0, each page switch also updates the URL making the URL bookmarkable. URLs can be copied and shared with others to share particular pages with them.
Updating URLs after switching pages also means that once the page is changed using the dropdown navigation, the browser’s page history based navigation can be used to go back to already visited pages.
Changing Page Layout
Each page uses a column layout of 1-4 columns. The number of columns for a page can be changed using top right Layout menu.
Changing the column layout of a page does not change the preferred position of the widgets. If a widget is set to column 3 but a 2-column layout is used all widgets of the 3rd or 4th column get pushed to the 2nd column instead. This allows switching layouts without redoing the configuration entirely.
Changing Page Update Interval
By default the graphs on a page update every 2 seconds. To control the interval use top right Data Refresh menu or open the Settings and change the interval in the Global settings.
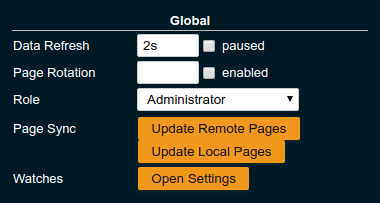
The interval can be paused and continued without changing the interval duration by using the paused checkbox next to the interval setting.
Adding Pages
To add a new page use the top right Page menu and select New….
This creates a new Unnamed page which can be renamed in the Page settings.
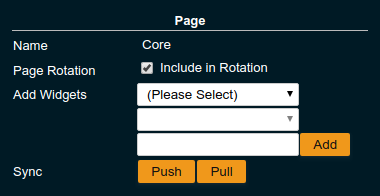
After naming the page add widgets.
Deleting a Page
To delete a page open top right Page menu, select Delete and confirm the browser confirmation dialogue.
| Pages that are based on a preset cannot be deleted. They can only be reset to default preset configuration. |
Reset a Page
When the configuration of a preconfigured page or any of the widgets on it was changed by the user the page can be reset by selecting Reset from the top right Page menu.
| The reset will affect all widgets and the general page settings of the currently shown page. All changes made by the user will be overridden. |
To reset all pages and remove all user created pages clear the browser’s local storage for the monitoring console page.
Page Synchronisation
Monitoring Console uses the browser’s local storage to store the page configuration (which includes the widgets placed on a page). This means by default changes to page configurations do not affect other users. To make pages available to others and to start from a common base configuration pages are explicitly synchronised with a persistent server page configuration.
The chosen role controls the behaviour and available options for the page synchronisation. It is the Administrator's role that is meant to manage the persistent server page configuration. The Administrator pushes local changes to the server to update the base configuration. Users and Guests pull the server configuration to update their local configuration with the base. The control remains with each user.
The Page Synchronisation dialogue shown when entering the console UI allows the user to pick the pages that should be updated (pulled).
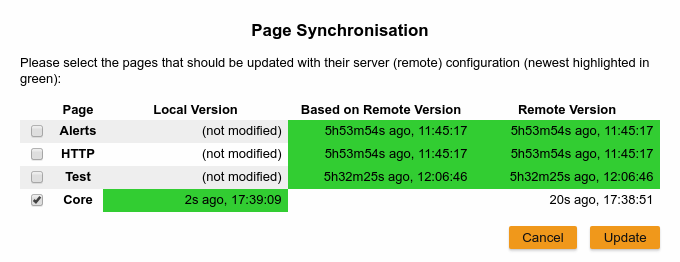
Based on the role the pages to synchronise are pre-selected.
-
Guest: by default updates all pages available remotely unless they are already up to date
-
Administrator and User: by default updates all pages available remotely unless a page has been locally changed
The newest version is marked by a green background for easier orientation.
This dialogue can also be opened from the Global settings by clicking the Update Local Pages button shown Page Sync property.
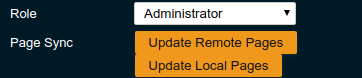
Administrators also find a button to Update Remote Pages with any changes applied to local changes. This is only needed for pages that are not using _auto_matic updates.
To share a page that so far is not part of the persistent remote configuration open the Page settings and look for the Sync property:

Users and Administrators can both Push a page to update the persistent remote configuration and Pull the remote configuration to update the local page. Administrators can also enable or disable the automatic page synchronisation. When enabled any local change done by an Administrator is automatically pushed to the remote configuration and can be pulled by other users.
Changing User Role
The monitoring console can be used in one of three roles:
-
Guest: A user that uses the console only on occasion to check existing metrics on existing pages ("read-only" user).
-
User: A user that uses the console to experiment with its features without affecting others.
-
Administrator: A user that uses the console to configure the configuration that is the basis for other users.
When no role is set for the session the user is asked to choose a role when opening the monitoring console.

The selection can be changed at any time in the Global settings for Role.
Widgets
Widgets are the components that can be placed on a page to show a particular metric. While there are different types of widgets usually a widget shows a line graph of one or more metrics for the entire cluster.
Adding a Widget
Widgets can be added to any page. Open the side panel by clicking on Settings top right menu. Use the dropdown in the Add Widgets property of the Page settings to select the category of the metric to add. This populates the second dropdown with all metrics for that category. Select a metric from the second dropdown to pre-fill the widget series name field below and press the Add button.
When added, widgets are automatically placed in a column so that they are evenly distributed on the page. Use the side panel widget settings to change column, span or item position of the widget or use the quick menu for the widget by clicking the cog symbol in the top right corner of the widget and select the action you want to apply to the widget.
| The widget series name field allows you to enter the name manually for advanced use cases or in case a metric is not available now but known to become available at some point. See Series with Wildcards for more details. |
Configuring a Widget
To configure a widget select it by clicking on its title.
This opens the side panel and shows the detail configuration of the widget. The side panel can be closed by either deselecting the widget, by clicking on its title again, or by clicking the Settings menu or its Hide item.
| If the settings have been opened explicitly through the Settings menu an empty selection will not close the settings side panel. |
The Widget settings are concerned with the widgets position within the page.
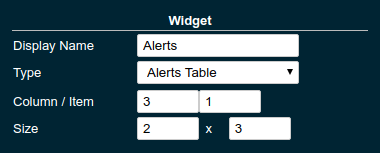
| Property | Default | Description |
|---|---|---|
Display Name |
(undefined) |
Optional name to customise the displayed widget title. If no name is given the Data Series is shown. |
Type |
|
Changes the type of graph used to show the metric. This also affects which data of the metric the widget is focussed on. Possible choices:
|
Mode |
(Default) |
If available for the type of widget the display mode can be switched between Table and List. Table view is best fitted for annotations that share common attributes, lists are better fitted for annotations with potentially differing attributes. |
Column |
1 |
The column in the layout the widget prefers to be in. |
Item |
1 |
Within columns widgets are sorted by their item value, lowest values first. The item position is automatically updated during page layout should it be needed. |
Size |
1 / 1 |
How many width (number of columns) and height (number of rows) the widget should span. Note that this is a target size. If page number of columns is reduced the width might be reduced to match the page layout. |
The Data settings are concerned with what and how the data is shown in the graph of a widget.
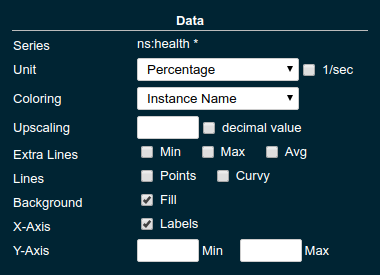
| Property | Default | Description |
|---|---|---|
Series |
- |
The metric key is given when adding the metric (read-only) |
Unit |
|
The unit controls how the raw number of a metric is interpreted and represented e.g. when displaying in axis labels. The unit also controls what values are accepted as input for numbers, like thresholds, that are on the same axis. Possible units are: |
Unit 1/sec |
|
Whether or not to show the metric as a change per second (delta between two points in the series normalised to average delta per second). |
Upscaling |
(undefined) |
When defined all values are multiplied by this factor. This can e.g. be used to move a decimal range between zero and one to a percentage range 0-100. |
Upscaling decimal value |
|
Check to mark the metric as one that is provided as a decimal value during collection (floats or doubles and alike). This will then revert the conversion applied during collection which converts decimal values to an integer number with 4 available decimal digits by multiplying them by 10,000. So this divides values by 10,000 again to move them back into their original value range. |
Extra Lines |
(none checked) |
Check to add the all time minimum, maximum or average line to the graph |
Lines |
(none checked) |
Options on how to display the current value line in the graph: Check Points to show individual data points on the line, check Curvy to use Bézier curves instead of straight line connections. |
Background |
Fill |
When Fill is checked the area between line and axis is filled. The background transparency can be configured globally in the Colors settings. |
X-Axis |
Labels |
Whether or not to show labels for the x-axis. |
Y-Axis |
(undefined) |
Set a minimum or maximum number for the y-axis instead. When not set range is derived automatically from the data points. |
Coloring |
Instance Name |
Used to select the colours the data is shown with. Instance Name will show data in the same colour that belongs to the same instance. Series Name shows the metric series in the same colour (independent of instance). This is individual to each widget. Result Set Index will show each matching series in a different colour. Instance and Series Name shows the same instance and series in the same colour. This is global. This means another widget using this colouring with the same instance and series will have the same colour as well. |
Fields |
(blank) |
A comma or space separated list of fields to show for an annotation list or table. The given field order is reflected in the view. |
Annotations |
(checked) |
Whether or not to show annotations for an alert table. |
Configuring Widget Decorations
Decorations are visual helpers that can be added to a graph of a widget in order to make it easier to for the user to quickly understand the data displayed. In particular these are reference lines.
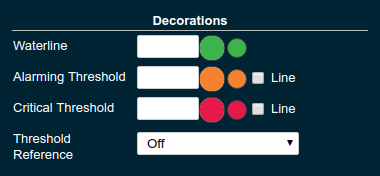
| Property | Default | Description |
|---|---|---|
Waterline |
(undefined) |
Adds a simple reference line that could mark a upper or lower limit. Enter in unit of y-axis, e.g. 20ms, 5s, 2GB, 4%, 123 |
Threshold Reference |
|
Controls what value the Alarming Threshold and Critical Threshold are compared to. Usually this is the most recent value but in some cases the all time minimum, maximum or average are useful too. |
Alarming Threshold |
(undefined) |
The limit for the "Alarming" state. If Critical Threshold is undefined or if it’s value is larger than this value the alarming threshold is exceeded if the reference value is larger than the threshold. Otherwise, if the Critical Threshold is lower than the Alarming Threshold, the threshold becomes 'inverse', and is exceeded when the reference value falls below the alarming value. When exceeded the status becomes "Alarming". Enter in unit of y-axis, e.g. 20ms, 5s, 2GB, 4%, 123 |
Critical Threshold |
(undefined) |
The limit of the "Critical" state. If Alarming Threshold is undefined or it’s value is smaller than this value the critical threshold is exceeded if the reference value is larger then the threshold. Otherwise, if the Critical Threshold is lower than the Alarming Threshold, the threshold becomes 'inverse', and is exceeded when the reference value falls below the critical value. When exceeded the status becomes "Critical", overrides status "Alarming". Enter in unit of y-axis, e.g. 20ms, 5s, 2GB, 4%, 123 |
Besides adding a reference line to the graph the critical and alarming thresholds affect the status evaluation.
Use the colour input to individually override the widget’s colour for waterline, alarming line or critical line in graphs. Press the button right next to it which shows the default colour as configured in the Colors settings to reset the individual colour to use the default setting instead. A colour set to the default changes with the default.
Configuring Widget Status Messages
The current value of a metric can automatically be categorised as a certain status. For example based on the threshold values of decorations or by encountered errors or missing data. The Status settings allows to set a custom message for a particular status.
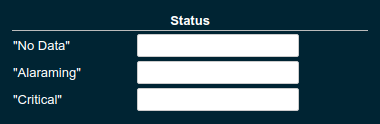
| Property | Default | Description |
|---|---|---|
"No Data" |
(undefined) |
The message to show when no data for a metric is available. For example to hint about configurations needed to make the metric available. |
"Alarming" |
(undefined) |
The message to show when the threshold got exceeded and the status evaluates to Alarming. |
"Critical" |
(undefined) |
The message to show when the threshold got exceeded and the status evaluates to Critical. |
The messages support simple markup using *bold* and _italic_.
Configuring Widget Alerts
The values of metric series can be tracked by the server to report values that out of a healthy range. This is represented by states:
-
Red: values in this range indicate an unhealthy state
-
Amber: values in this range indicate a degraded state
-
Green: values in this range indicate a healthy state
-
White: values in this range are in no particular state (neither good or bad, maybe undecidable)
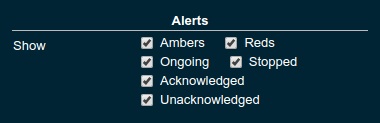
| Property | Default | Description |
|---|---|---|
Show |
(all checked) |
Filters that allow to control the type of alerts that should be shown. Include Amber and/or Red alerts, Ongoing and/or Stopped alerts, Acknowledged and/or Unacknowledged alerts. If for any of these 3 groups of pairs both are unchecked the list will be empty. Widgets of type Time Curve automatically exclude stopped and acknowledged alerts to avoid cluttering the graph with alerts that aren’t relevant any more. Use a widget of type Alerts Table to show all alerts according to the filter at all times. |
Handling Alerts
Alerts can occur when a watch is configured for a metric series. A watch describes the conditions and thresholds used to determine a state from the recent values of a metric series. It is either Red (unhealthy), Amber (degraded), Green (healthy) or White (undetermined). A Red or Amber state causes an alert that is shown on top of the graph.
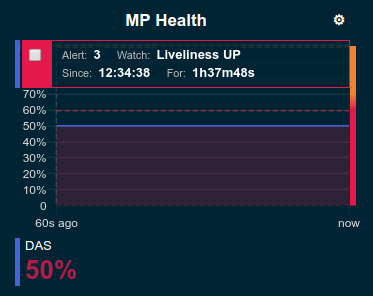
When an alert occurred for a metric shown in a graph the background of the line causing the alert is coloured in Red or Amber default colour until the alert is stopped.
Alerts are considered ongoing as long as the state is Red or Amber. If it is evaluated to Green or White the alert stops. Stopped alerts are no longer shown on top of line graphs. Another way to remove an alert from the line graph is to acknowledge the alert by checking its checkbox. To see even stopped or acknowledged alerts add a widget of type Alert Table.

By default an alert table shows all alerts including stopped and acknowledged alerts. Use the widget Alerts settings to exclude alerts with certain properties.
Alert table shows the overall state of each instance in the table’s legend.
Alerts settings can equally be used for line graphs to create a more restrictive setting.
| Currently watches are only added programmatically as part of the server. User defined watches are not yet possible. |
Removing a Widget
Any widget can be removed from any page. Click the cog symbol in the top right of the widget, select Remove and confirm the browser dialogue.
Remember that a page originating from a preset can be reset to recover a widget that was removed accidentally.
Using Advanced Data Series
A series is a name or key for a particular metric shown in a widget. Each metric has a unique key or series name. Usually these names use tags to categorise metrics into groups. For example:
ns:jvm MetricName ns:jvm @:groupName MetricName
The patterns shown above exemplify conventions used throughout Payara monitoring console.
The first grouping level usually is the ns (short for namespace), the second the @ (short for group).
In the example the metrics belong to the jvm namespace and the groupName group within that namespace.
When metrics are selected using the dropdowns these details are filled in for the user by selecting items from the dropdowns.
Alternatively, a user may choose to enter the series key manually which allows using a wild-card star instead of either a tag value (like jvm) or the MetricName. For example:
ns:jvm @:* Duration
This will then match all existing series that match the pattern. This feature can be used to automatically show all metrics of a certain pattern in a single widget as it is done by the request tracing page.
Global Configurations
The configuration that controls the monitoring console UI. It is stored in the browser’s local storage. For manual sharing the configuration can be exported and imported in the form of JSON files. Server integrated sharing can be done using the built in page synchronisation which is a two-way update mechanism to update either the local configuration with server configuration or the other way around which allows the sharing of changes made by one user with other users in a more convenient way.
| Property | Default | Description |
|---|---|---|
Data Refresh |
|
Interval duration used to update the currently shown page with new data (poll duration). To pause any page update check enabled checkbox. |
Page Rotation |
(undefined duration) |
Duration each page is shown during page rotation. To run a rotation enter a interval duration using a number with time unit and check the enabled checkbox. To stop rotation un-check the enabled checkbox. |
Role |
User |
Select the used user role. See section Changing User Role for details. |
Page Sync |
- |
Update Local Pages button opens the dialog to pull page configuration updates from server (not available to Guest role). Update Remote Pages button pushes changes to local pages to remote (server) if such a page already exist remotely (Administrator role only). |
Watches |
- |
Just a short-cut to the watches configuration page |
Export Configuration
A configuration contains all pages. All changes made to a page or widget setup are contained in this configuration. To download this configuration as JSON file select Export from the Settings top right menu.
Import Configuration
To import a previously exported JSON file select Import in the top right Settings menu and select the JSON file to import. This feature can be used to version and distribute configurations for similar installations.
| Importing files will override any changes made to pages existing in both the current configuration and the imported file. Importing pages will not remove pages that are not contained in the imported file. |
Page Rotation
Monitoring console is built with the intention of being used to display metrics on status monitors. To allow viewing a variety of pages and their metrics on a single screen the pages can be automatically rotated showing each page for a configured interval duration.
To enable page rotation open the Settings and check the enabled checkbox in the Global Settings Page Rotation property. This starts the rotation immediately.
The duration can be adjusted changing the text field of the Page Rotation to another time value. Use units to express the duration, as for example: 1min, 30sec.
Changes take effect immediately.
The rotation will show each page for the configured duration. Pages can be excluded from rotation by switching to the page using the page menu. Open the Settings and uncheck the Include in Rotation checkbox in the Page settings.
Color Configurations
Newer versions of the Monitoring Console allow to configure the colours used in graphs. There is a global colour configuration affecting all graphs.

| Property | Default | Description |
|---|---|---|
Scheme |
- |
The selected scheme is applied to set the colours palette for Data as well as Defaults and Opacity. This is only a convenient way to switch all of these between different settings. The individual properties can be changed afterwards as usual without affecting the scheme. |
Data # (Palette) |
(colours of Payara scheme) |
The list of colours to use when colouring data series in graphs. This is the line colour in line charts or the bar colour in bar charts. Background will use the same colour with Opacity. Add new colours by using the |
Defaults |
(default of Payara scheme) |
Sets the default colours for Waterline, Alarming and Critical as well as Red, Amber, Green and White state lines, backgrounds and texts. Some of these can be individually overridden in the widget’s configuration for these lines. |
Opacity |
10 |
Background opacity for lines or bars in graphs, 0 (fully transparent) to 100 (solid). |
Thickness |
(3) |
Line width on a scale 1-8. Each point corresponds to 0.5px with. Default for lines in a line graph is 3, so 1.5px. |
User Defined Watches
A watch describes the conditions to meet to start and stop alerts in relation to a specific metric. For example to get an alert every time an HTTP request causes a server error (responds with any of the 5xx status codes) a custom watch is installed. This is very similar to a custom health check that could be linked to any metric available where the thresholds are defined as part of the watch. There are many varieties of conditions that can be formulated. Each watch has a start condition which when met starts a new alert. Optionally a stop condition can be given which when met will stop the alert. If no such stop condition is given an alert stops as soon as its start condition is no longer met. Such pairs of start and stop conditions can be defined for 3 levels:
-
Unhealthy: corresponds to a "red" alert
-
Degraded: corresponds to an "amber" alert
-
Healthy: conditions for particularly good values, these will not cause alerts but can be used to mark a healthy range in graphs.
Each watch must have at least an Unhealthy or a Degraded condition. When both are given alerts can transition between Degraded and Unhealthy as the same issue or alert. Unhealthy takes precedence over Degraded and Healthy, Degraded takes precedence over Healthy should their condition be met at the same time. Should a Degraded alert be acknowledged but it transitions to Unhealthy afterwards the acknowledgement is reset so this change is not missed.
Creating a Watch
To create custom watches go to the Watches page using the top page menu or the Global settings.

The above example shows a relatively simple watch named HTTP server errors. The name of the watch can be anything as long as it is unique. The watch should have both a Unhealthy and a Degraded level.
The field after the If holds the name of the metric series the watch is linked to, in this case the ns:http ServerCount5xx metric, as shown on the HTTP page. The in clause specifies the unit type of the given metric, here it is the Count of 5xx responses. Following is the comparison operator is selected, here >. This is followed by the threshold value, here 3 or 1, and the scope of the comparison, here in sample.
As both do not use a stop condition the checkbox after until is not checked.
The below table describes possible choices for each step of a watch condition.
| Segment | Start/Stop | Description |
|---|---|---|
|
Both |
Give the name of the metric series to watch. As monitoring is a generic, dynamic and open system there is no definitve pre-defined list of available metrics. The metrics currently available are listed at http://localhost:8080/monitoring-console/api/series/ (assuming DAS runs on localhost). |
|
Both |
Select the unit for the given metric series. This should be the same unit given in widget configuration Data property Unit. Depending on the chosen unit the threshold can be given in values of this unit, e.g. when selecting Milliseconds the threshold can be given as |
|
Start |
Select the comparison operator to use when comparing the actual value(s) to the threshold. The comparison is of form actual operator threshold. |
|
Start |
The numeric threshold. The upper/lower limit. With the right unit selected the number can be given with a unit such as |
|
Start |
Select a scopes for the actual values that are compared to the threshold. The semantics of the different scoped are described in a separate table below. |
|
Start |
The length defines how many of the most recent data points of the watched metric are included in the scope of the comparison. A number with time unit refers to the number of the points, a number with time unit to the duration of points to consider for the scope. |
|
Stop |
same as for start |
|
Stop |
same as for start |
|
Stop |
same as for start |
The below table describes the semantics of the different types of comparison scopes.
| Scope | Description |
|---|---|
|
The comparison must be true for each point in the scope for the condition to be met. Similar to a all logic. The number of points included is specified afterwards. This is either a bare number referring number of points to include or a number with a time unit referring to a duration where all points within the duration from most recent point backwards are included in the scope. |
|
The comparison must be true for the single average value of all points in the scope for the condition to be met. The number of points included is specified afterwards as number of duration from which to consider points. |
|
The comparison must be true for at least one of the points included in the scope for the condition to be met. Similar to an any logic. The number of points included is specified afterwards as number of duration from which to consider points. |
|
The comparison must be true for at least one of the points available for the condition to be met. For this scope type no length is given as all available points are considered. This can vary but usually consists of the last minute of data. |
After composing the watch conditions press Save or Update to install the watch. If a watch of the same name already exists the existing watch is replaced. Watches that originate from server modules cannot be replaced. To change them disable the existing watch and click to edit it, this will create a duplicate with a different name that can be adjusted freely.
Editing a Watch
To edit a previously created watch click on its name in the list of watches or chose Edit from the cogs menu on the right.
Watches that originate from server modules cannot be edited. When clicking their names or when choosing Duplicate from their cogs menu a duplicate with a different name is created. The suggested name Copy of {original name} can be changed as long as it is different to existing watch names.
When changing the name of an edited watch to an existing name this overrides that watch. In other words watches are always identified by their name.
Disabling or Enabling a Watch
Go to the Watches page using the top page menu or the Global settings.
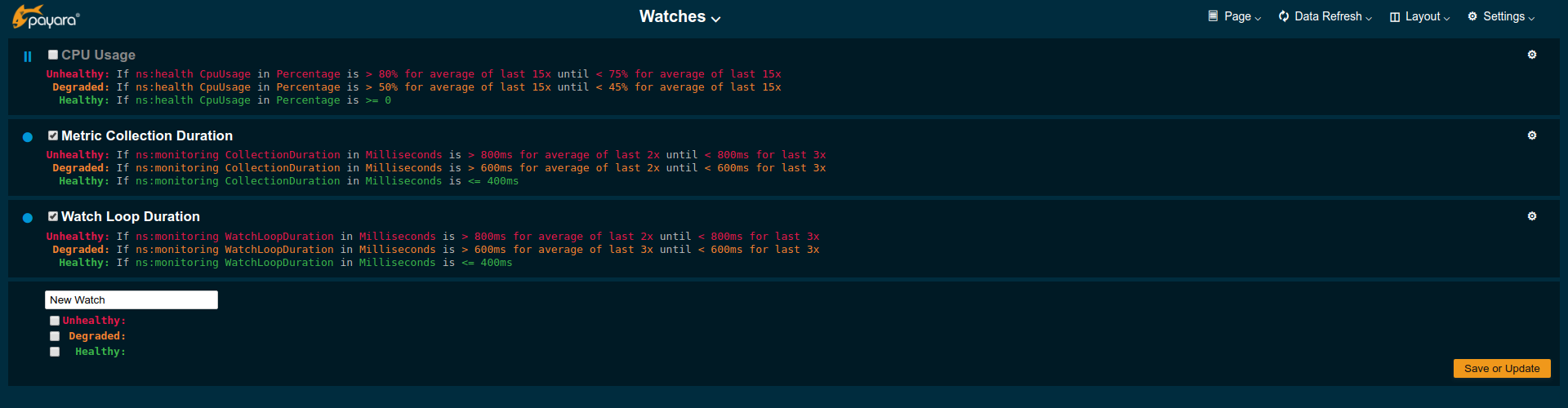
The status of each watch is reflected by the checkbox left of the watches name, checked for enabled, unchecked for disabled. Disabled or stopped watches names are also greyed out. To disable an enabled watch un-check the checkbox or use the Disable item from the cogs menu on the right of the watch widget. To enable a disabled watch check the checkbox or use the Enable item from the cogs menu. The change has immediate effect.
Preconfigured Pages
Core Page
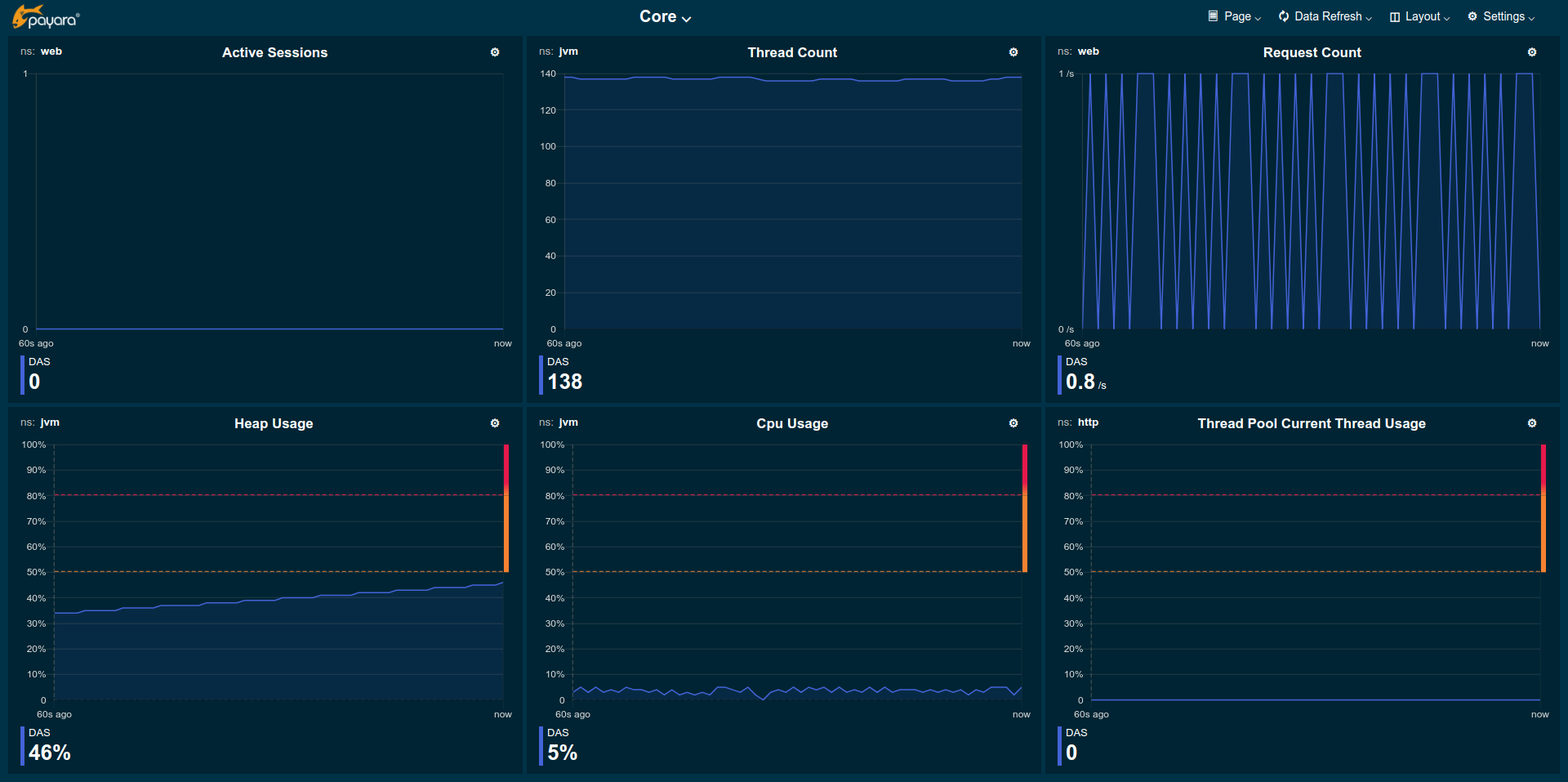
The Core page gives an overview of some of the important instance metrics. Each instance in the grid is shown separately.
-
Active Sessions: Total number of active session for the instance.
-
Thread Count: Total number of threads used by the instance.
-
Request Count: Number of HTTP request per second processed by the instance.
-
Heap Usage: Percentage of the current instance maximum heap memory already used.
-
CPU Usage: Percentage CPU usage by the instance (not the machine but the process).
-
Thread Pool Current Thread Usage: Percentage of HTTP thread pool threads currently in use by the instance.
HTTP Page
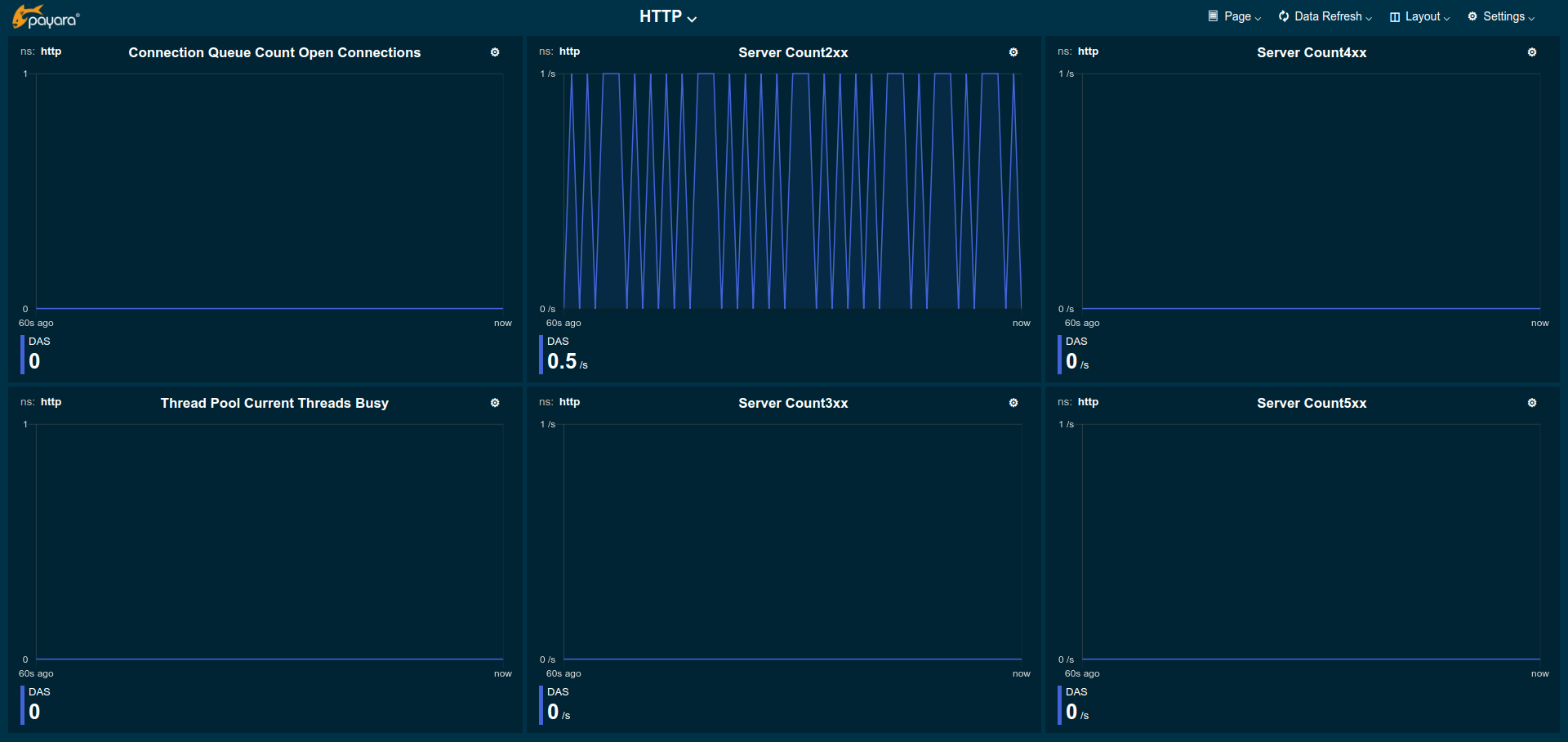
The HTTP page gives a rough overview of the state of the HTTP services of each instance.
-
Connection Queue Count Open Connections: Total number of open connection in the connection queue
-
Thread Pool Current Threads Busy: Number of threads in the HTTP thread pool currently processing a HTTP request.
-
Server Count2xx: Requests per seconds and instance responding with Success.
-
Server Count3xx: Requests per seconds and instance responding with Redirection.
-
Server Count4xx: Requests per seconds and instance responding with Client Error.
-
Server Count5xx: Requests per seconds and instance responding with Server Error.
JVM Page
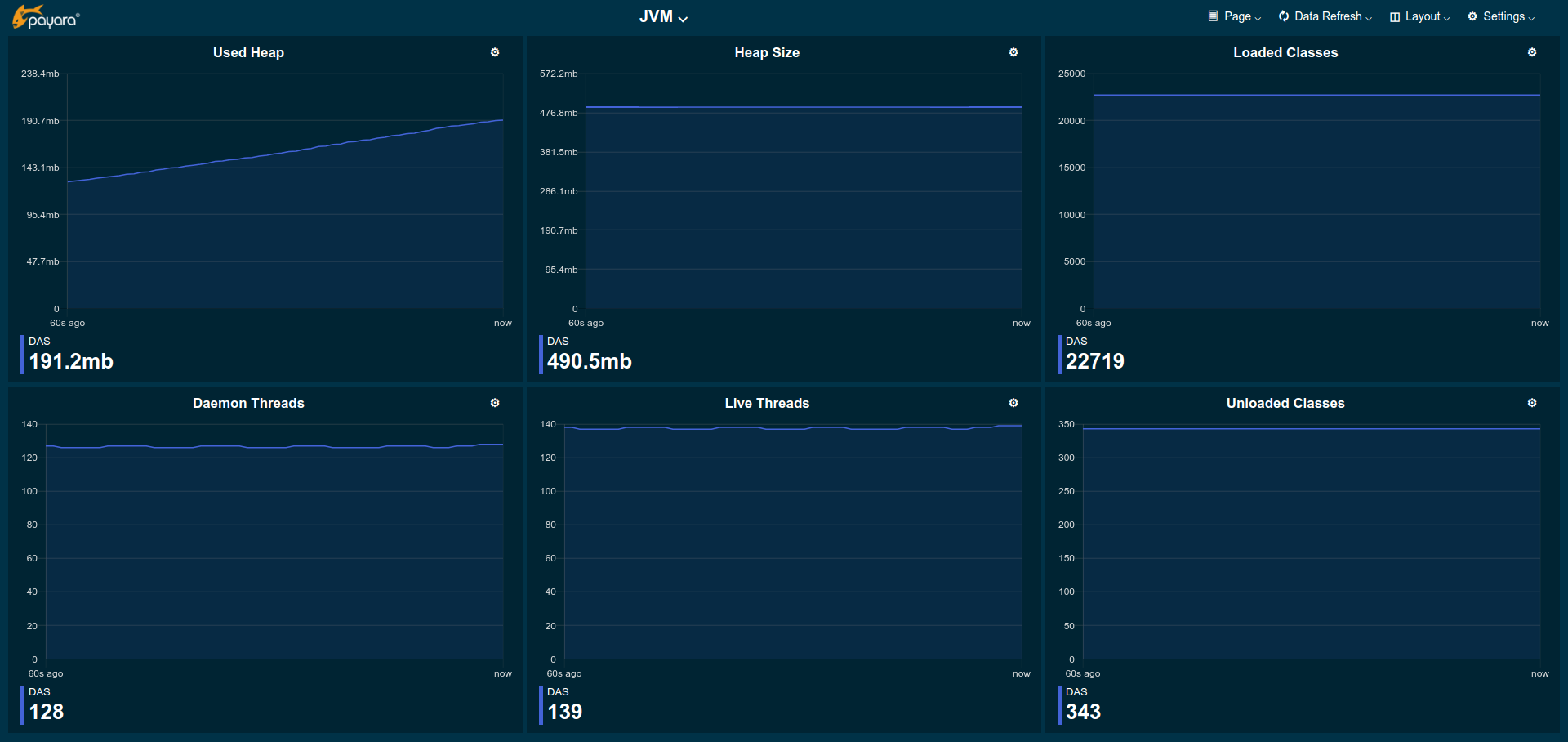
The JVM pages gives a general overview of the state of the JVM running Payara Server Enterprise.
-
Used Heap: Total size of the used heap memory
-
Heap Size: Size of the committed (reserved) heap memory (OS level)
-
Loaded Classes: Total number of loaded classes
-
Unloaded Classes: Total number of unloaded classes
-
Live Threads: Total number of threads used by the JVM (including daemon threads)
-
Daemon Threads: Total number of daemon threads used by the JVM
Monitoring Page
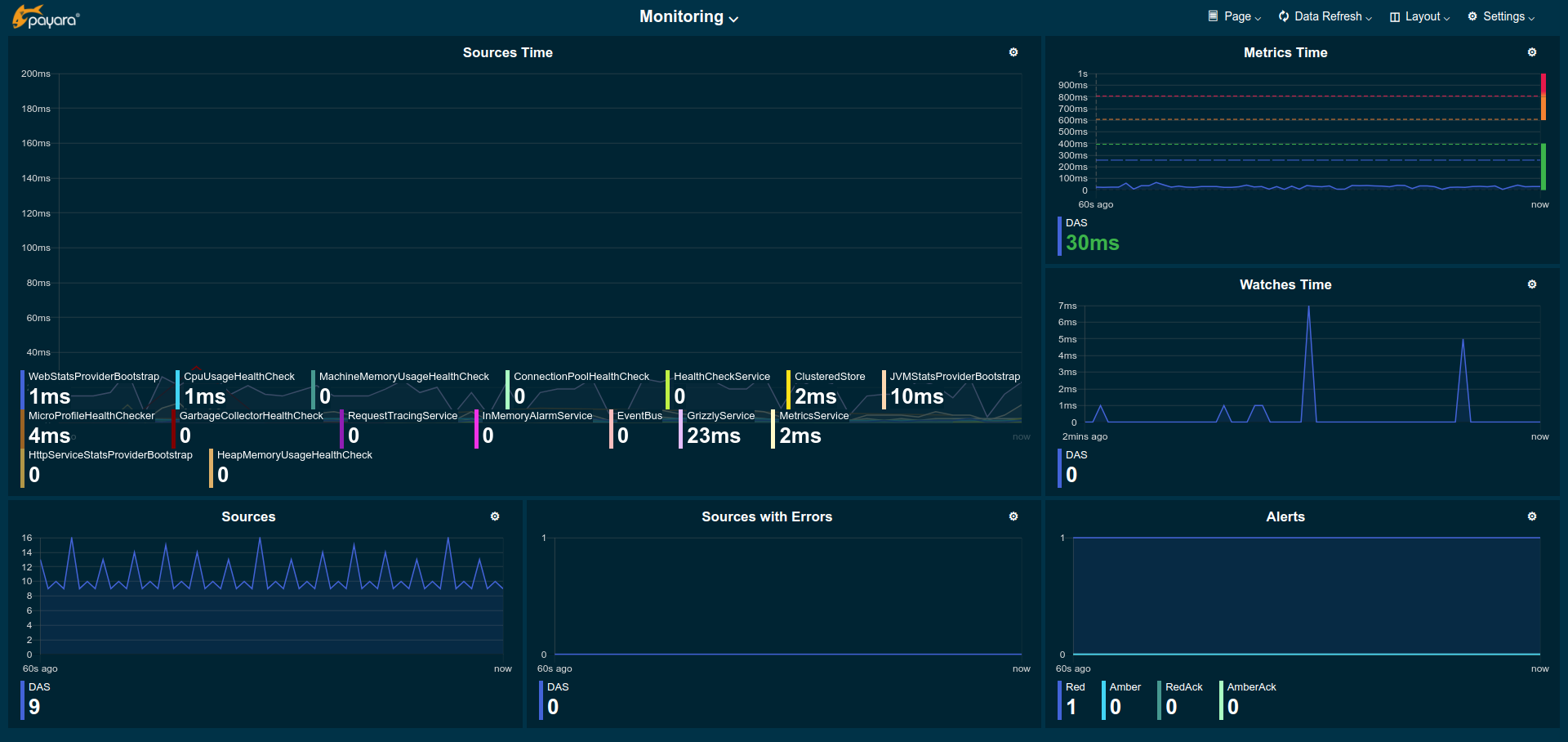
A page that shows key metrics on the monitoring system itself that feeds the monitoring console with data. This is mostly useful to identify problems with the monitoring system or to cross check that unexpected metric values aren’t caused by general problems with monitoring.
-
Source Times: Shows the duration it took to collect metric data from the individual sources within the server. Durations should be well below a second. Usually in two digit millisecond range.
-
Sources: Number of sources metrics are collected from in a particular second. This varies as some sources are collected in an interval of several seconds.
-
Sources with Errors: Shows how many of the sources that were collected caused an error during collection that potentially ends the collection of that source so that some metrics usually provided by that source might no longer be collected. This can explain missing metrics.
-
Metrics Time: The total time it took to collect all sources. As collection happens once every second this should be well below 1 second. This metric is watched and alerts are created should the time exceed 600ms for multiple times in a row. This time can vary a lot depending on the server configurations as sources are enabled and disabled. It can also be influenced strongly by the deployed applications as they can contribute metrics in large numbers.
-
Watches Time: The total time it took to collect and evaluate all watches. This time is less critical but it should usually be well below 1 second. Typically in the range of two digit milliseconds.
-
Alerts: The total number of ongoing (active) alerts.
Health Checks Page
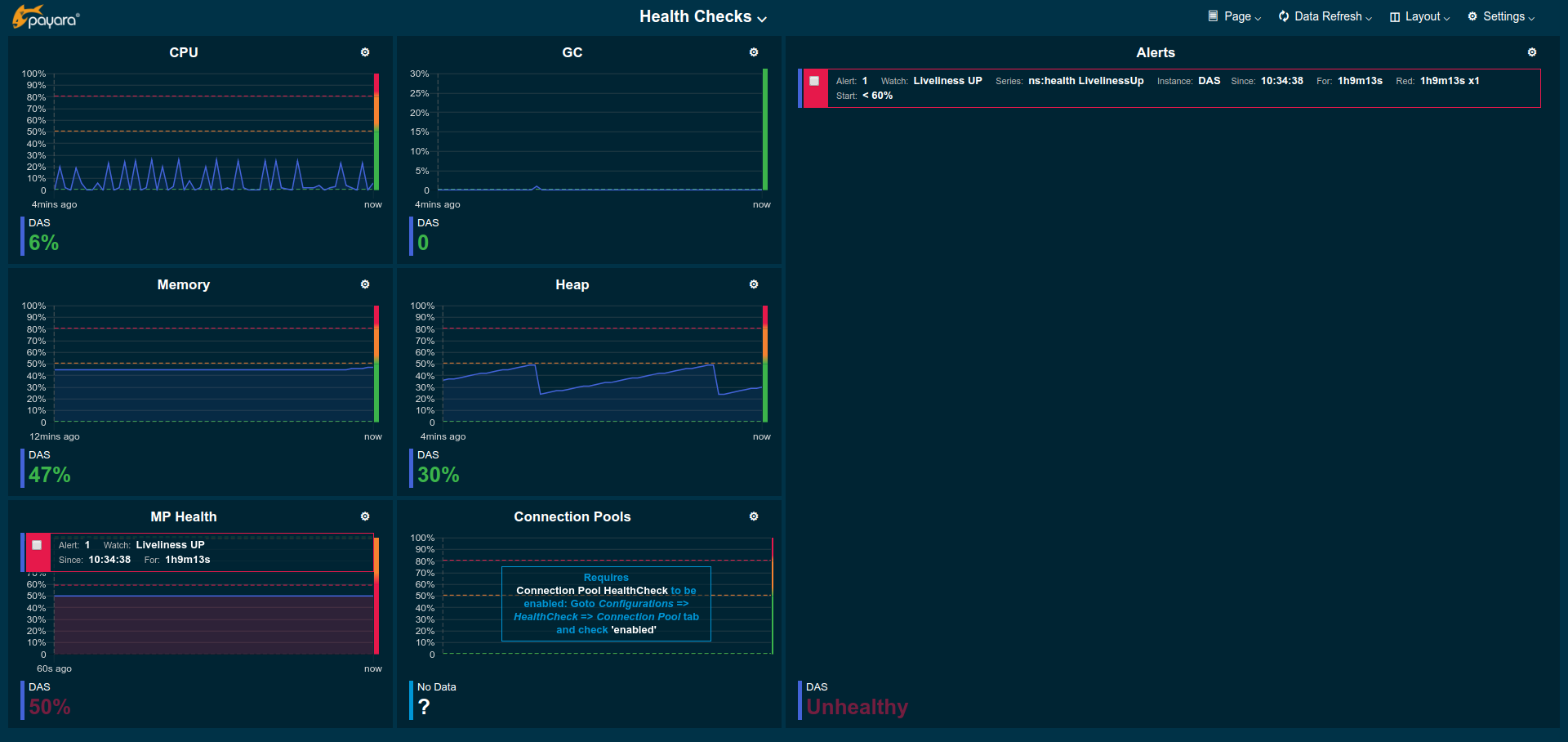
A page that gives an overview of the state of the server health checks. The individual checks need to be enabled in the server HealthCheck configuration.
| It is not required to enabled the HealthCheck service in the general tab in case the checks should only be enabled for metrics based monitoring without causing health check notifier messages. |
-
CPU: CPU Health Check, percentage of CPU used by the server instance during last 4 seconds
-
GC: Garbage Collection Health Check, percentage of time used to collect garbage objects during the last 4 seconds
-
Memory: Machine Memory Usage Health Check, percentage of the total available physical memory used
-
Heap: Heap Memory Usage Health Check, percent of total available heap memory used by the JVM
-
MP Health: MicroProfile Health Check, percent of instances that respond with
UPstatus to a liveliness health endpoint request (this includes the DAS that is the only instance that is performing this check every 12 seconds) -
Connection Pool: Connection Pool Health Check, percent of connections currently used for each JDBC connection pool
-
Alerts: A list of all health check related alerts
Thread Health Page
The Threads page gives detailed information on thread health of the cluster and lists information on stuck or hogging threads. Total number of live and daemon threads are given for reference.
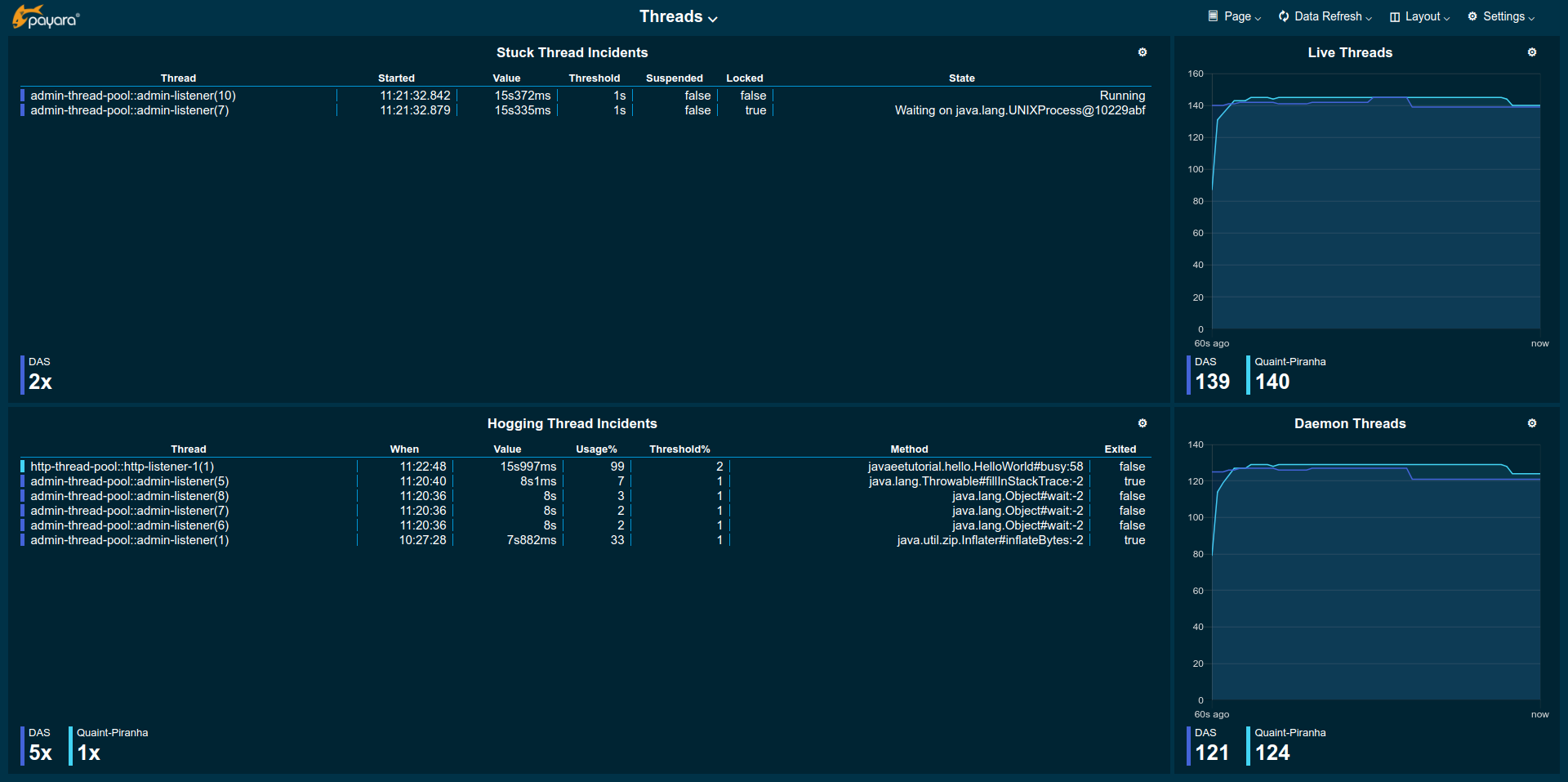
-
Stuck Thread Incidents: Table listing the most recent information for threads that are considered stuck. This is the case if the time passed since a thread started a not yet finished unit of work becomes longer than the set threshold in the Stuck Threads health check configuration. This could be because it is waiting at a lock or the operation takes a considerable amount of time.
-
Hogging Thread Incidents: Table listing the most recent information for threads that are considered hogging. This is the case if the thread’s use of the CPU in percent points is higher than the threshold value configured in the Hogging Threads health check configuration for n times in a row, where n is 1 + the configured number of retries.
-
Live Threads: Total number of threads used by the JVM (including daemon threads)
-
Daemon Threads: Total number of daemon threads used by the JVM
| Be aware that the number shown in the example image are not characteristic. For demonstration purposes the thresholds have been set uncharacteristically low to be able to "force" entries. Usually the threshold for stuck threads should be in region of some seconds to a few minutes. The threshold for hogging threads should be well above 90% with a few retries. |
Request Tracing Page
The Request Tracing page overview page shows traces that exceeded the set threshold.
| If this page does not show any data, no request has exceeded the threshold or the request tracing has not been enabled. Check Configuration ⇒ Request Tracing. |
The Trace Duration Range widget shows all traces for the same method as a single bar. The length and position of the bar gives the range of total trace duration for all the occurrences that exceeded the threshold. The bar starts at the minimum duration observed and ends at the maximum duration observed in the last minute. The legend shows the average duration and the method traced (innermost trace span operation)
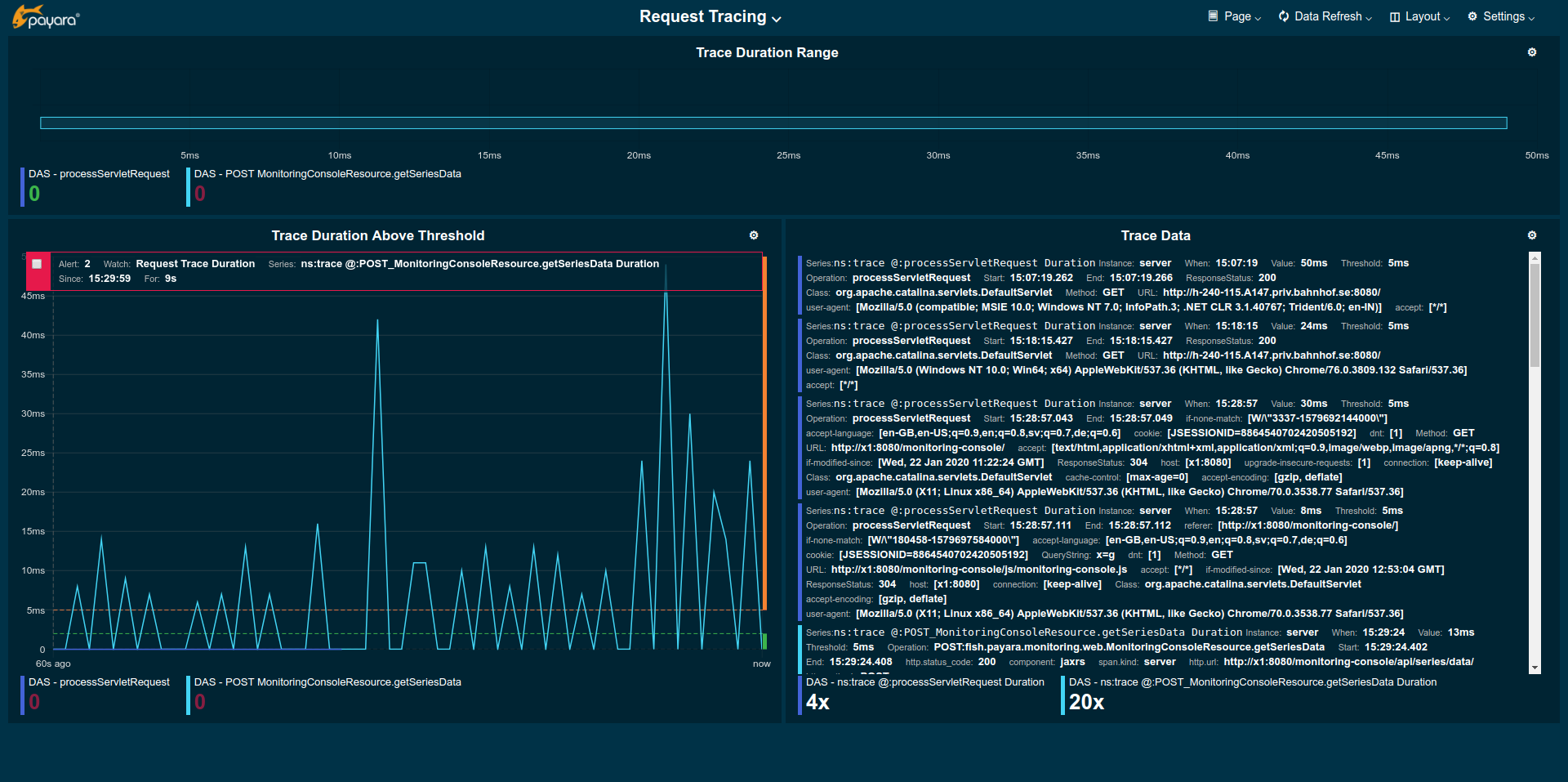
When all time minimum and/or maximum are added in the Widget Data settings the bar starts and/or ends at these "all time" values instead of the minimum and/or maximum within the last minute.
The Trace Duration Above Threshold widget shows a graph where each point marks the duration of a "slow" request at the moment the requests occurred. Possible alerts are shown on top of the graph.
The Trace Data view adds tracing details for the "slow" requests that can be sorted by wall-time or value using the widget menu (gear icon in top right corner of the widget).
By clicking on one of the bars in the overview’s Trace Duration Range widget the details of all kept traces for this method can be viewed. This data corresponds to the traces stored in the trace-store. For each trace, each of the spans corresponds to a bar in this graph.
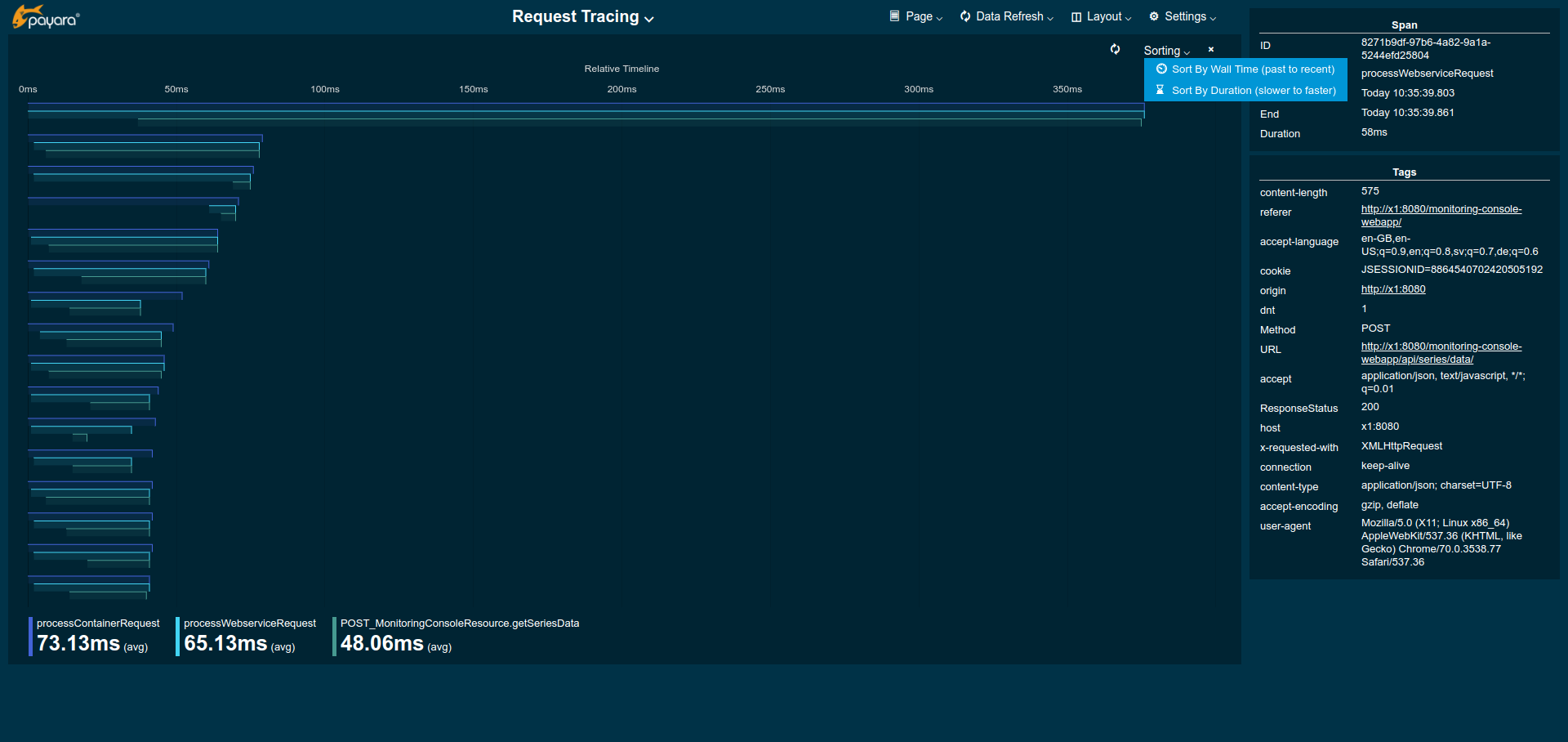
By default the traces are sorted longest (slowest) to shortest (fastest) total duration. On the time axis the spans are shown relative to the start of the trace.
When the side panel is opened the details of each trace span can be viewed by clicking on the span bar.
The legend gives average durations for each of the spans occurring for the traced method.
| The detail view does not automatically refresh. To refresh click the refresh icon next to the Sorting menu in the top right of the widget. |
The spans can be sorted by wall time by selecting Sort by Wall Time or by duration by selecting Sort By Duration in the Sorting menu in the top right of the widget.
To get back to the overview close the details by clicking the x-icon on the right side of the Sorting menu.
| Be aware that the graphs in the example images above show unrealistically low numbers due to the way that request tracing was configured. In a more realistic configurations the durations are more likely to be in range of few hundred milliseconds to some seconds. |
SQL Page
The SQL page gives insight into slow SQL queries for all connection pools configured in Payara Server Enterprise.
| To capture slow SQL queries the JDBC Connection Pool configuration’s Slow Query Log Threshold in the Advanced tab needs to be set to a positive number. |
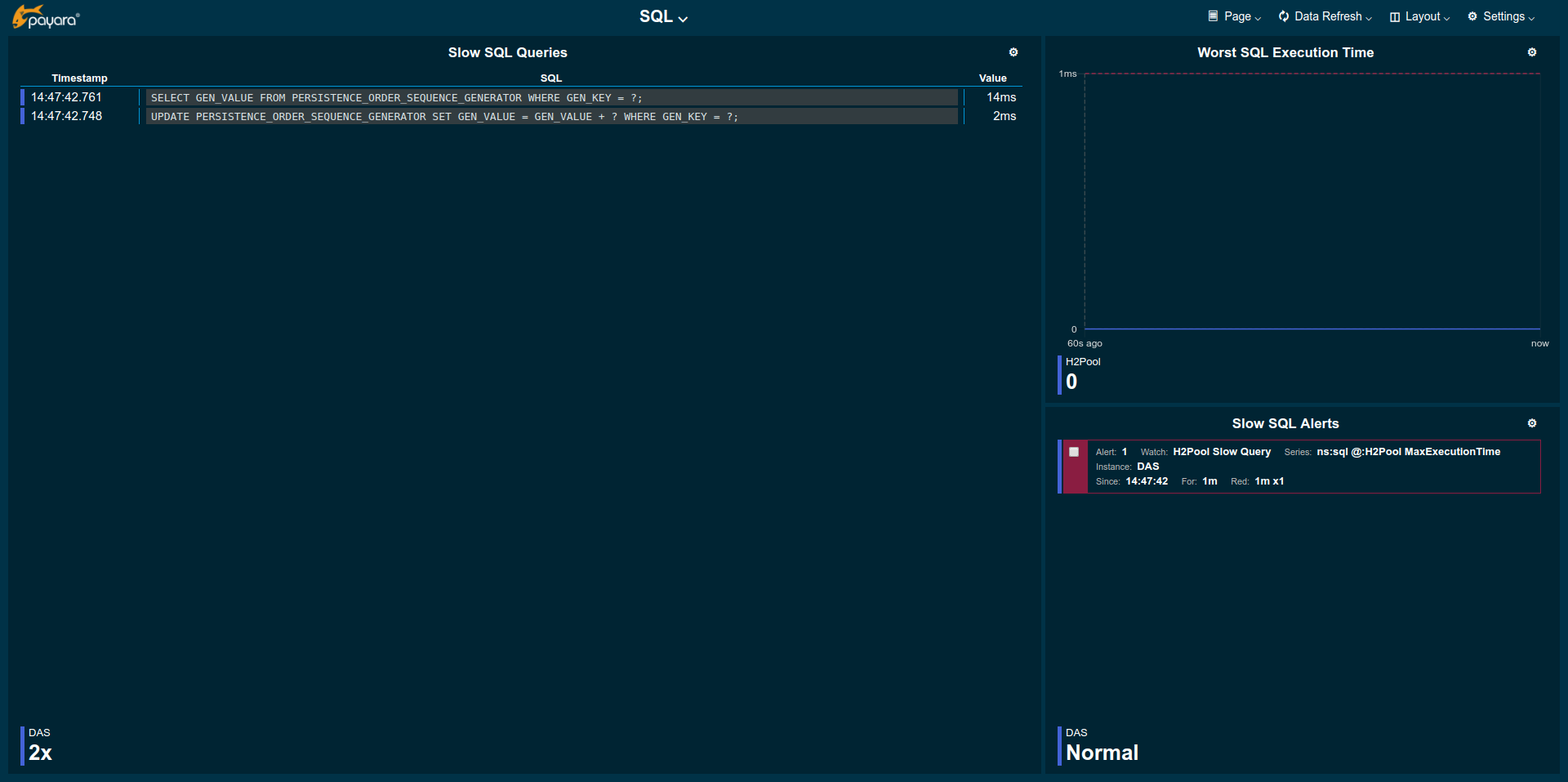
-
Slow SQL Queries: Shows SQL details for queries that were too slow. Value refers to the duration of the SQL query.
-
Worst SQL Execution Time: Shows SQL query activity. Each data point gives the duration of the slowest query run during last second. Zero means no SQL query was run.
-
Slow SQL Alerts: A list of alerts caused by too slow SQL queries in reference to the Slow Query Log Threshold given in the pool configuration. Single outliers cause a degraded state (amber alerts), outlier groups cause unhealthy state (red alerts).
Alerts Page
The main use of the Alerts page is to check for any server alerts. The page is split into two lists: the upper list containing all ongoing alerts, and the lower list containing past alerts. As always for alert lists both lists are sorted starting with the most recent severe alert progressing to the oldest least severe alert. Annotations associated with alerts are hidden in this view to make room for more alert entries.
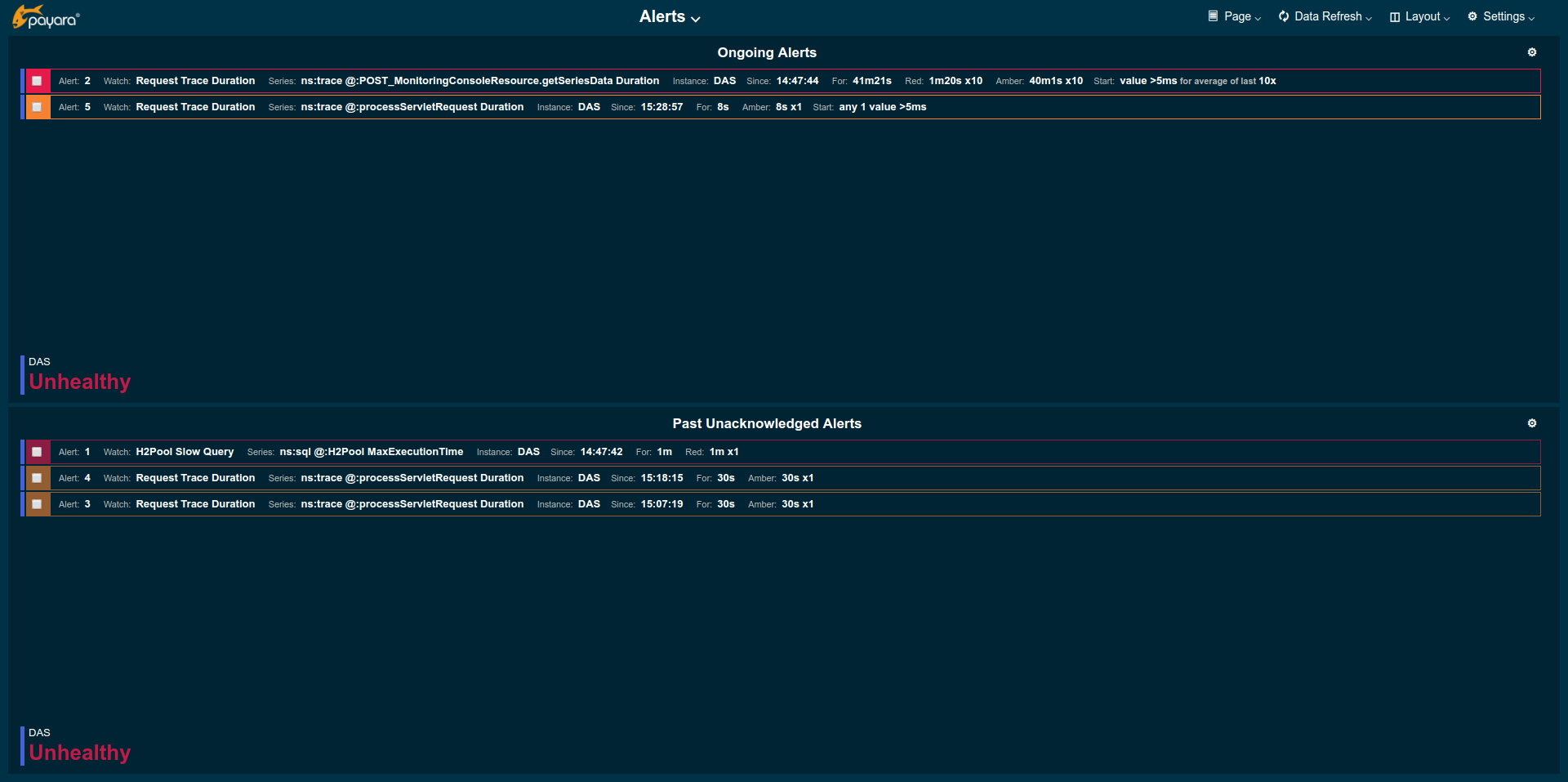
Past alerts can be managed by acknowledging the alerts which makes them disappear from the list.
User Defined Metrics
Payara monitoring console is build with the intention to allow user defined metrics to be visualised. So far these include the MicroProfile Metrics that might originate from a deployed application and other extensions of the server. These are included in the available metrics automatically.
Open the Settings and look for MP Metrics in the topmost dropdown for the Add Widgets property in the Page settings.
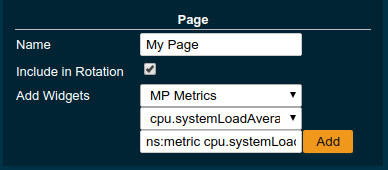
The metrics found in the second dropdown originate from existing MicroProfile Metrics defined in the server.
Eventual MP tags used become the @ group of the shown series key, the MP metric stays the metric name.