This chapter describes how Jakarta Enterprise Beans (EJB) technology is supported in the Payara Platform.
For general information about enterprise beans, see "Enterprise Beans" in The Jakarta EE Tutorial.
|
The Web Profile of the Payara Server supports the EJB 4.0+ Lite specification, which allows enterprise beans within web applications, among other features. The Full Profile supports the entire EJB 4.0+ specification. For details, see Jakarta Enterprise Beans. |
Payara Server is backward compatible with 1.1, 2.0, 2.1, 3.0, 3.1 and 4.0 enterprise beans. However, to take advantage of version 3.1+ features, you should develop new beans as 3.1+ enterprise beans.
Customized EJB-JAR Archive Names
It is possible to instruct the server runtime to override the name of an EJB-JAR module when it is deployed either as a standalone module or as part of an EAR application. It is also possible to instruct Payara Server to override the module and/or application’s name.
Overwriting the Module Name
When deploying an EJB-JAR module on Payara Server/Micro, the portable JNDI names for all scanned EJBs will be generated using the name of the module as specified on the ejb-jar.xml deployment descriptor:
<?xml version="1.0" encoding="UTF-8"?>
<ejb-jar xmlns = "https://jakarta.ee/xml/ns/jakartaee"
version = "4.0"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation = "https://jakarta.ee/xml/ns/jakartaee https://jakarta.ee/xml/ns/jakartaee/ejb-jar_4_0.xsd">
<module-name>MODULE_NAME</module-name>
</ejb-jar>| If the name’s not specified in the deployment descriptor, the specification states that the module name will be the same as the JAR artifact used to deploy it. |
However, when deploying a JAR from an IDE (like NetBeans or IntelliJ), the IDE deploys to Payara Server using the asadmin deploy command, with the --name option specified. This will force the module to have the specified name over the name defined in ejb-jar.xml. This is undesired because the IDE usually infers the module name from the name of the project or the JAR file and doesn’t take the correct name of the module into account.
The module name defined in the deployment descriptor will be used even if it tries to be overridden using the --name option. This behaviour will always take precedence.
In the case you need to overwrite the name of the module when deploying the module, use the --forceName command option.
|
Overwriting the Application Name
In the case of EAR artifacts, the portable JNDI names for all scanned EJBs will use the application name defined in the application.xml deployment descriptor:
<?xml version="1.0" encoding="UTF-8"?>
<application xmlns="https://jakarta.ee/xml/ns/jakartaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="https://jakarta.ee/xml/ns/jakartaee https://jakarta.ee/xml/ns/jakartaee/application_10.xsd" version="10">
<display-name>My Application</display-name>
<application-name>APPLICATION_NAME</application-name>
</application>
You can use the --name and --forcename deployment options to override the application name in a similar manner with what happens with EJB-JAR modules.
|
Value Added Features
The Payara Platform provides a number of value additions that relate to EJB development. References to more in-depth material are included.
Read-Only Beans
Another feature that Payara Server provides is the read-only bean, an EJB 2.1 entity bean that is never modified by an EJB client. Read-only beans avoid database updates completely.
|
Read-only beans are specific to the Payara Platform and are not part of the Enterprise JavaBeans Specification, v2.1. Use of this feature for an EJB 2.1 bean results in a non-portable application. To make an EJB 3.0 entity read-only, use @Column annotations to mark its columns insertable=false and updatable=false.
|
A read-only bean can be used to cache a database entry that is frequently accessed but rarely updated (externally by other beans).
When the data that is cached by a read-only bean is updated by another bean, the read-only bean can be notified to refresh its cached data.
Payara Server provides a number of ways by which a read-only bean’s state can be refreshed. By setting the refresh-period-in-seconds element in the glassfish-ejb-jar.xml file and the trans-attribute element (or @TransactionAttribute annotation) in the ejb-jar.xml file, it is easy to configure a read-only bean that is one of the following:
-
Always refreshed
-
Periodically refreshed
-
Never refreshed
-
Programmatically refreshed
| Read-only beans are best suited for situations where the underlying data never changes, or changes infrequently. For further information and usage guidelines, see Using Read-Only Beans. |
The pass-by-reference Element
The pass-by-reference element in the glassfish-ejb-jar.xml file allows you to specify the parameter passing semantics for co-located remote EJB invocations. This is an opportunity to improve performance.
However, use of this feature results in non-portable applications. See "pass-by-reference" in the Payara Server Application Deployment section.
Pooling and Caching
The EJB container of Payara Server pools anonymous instances (message-driven beans, stateless session beans, and entity beans) to reduce the overhead of creating and destroying objects.
The EJB container maintains the free pool for each bean that is deployed. Bean instances in the free pool have no identity (that is, no primary key associated) and are used to serve method calls. The free beans are also used to serve all methods for stateless session beans.
Bean instances in the free pool transition from a Pooled state to a Cached state after ejbCreate and the business methods run. The size and behavior of each pool is controlled using pool-related properties in the EJB container or the glassfish-ejb-jar.xml file.
In addition, Payara Server supports a number of tunable parameters that can control the number of "stateful" instances (stateful session beans and entity beans) cached as well as the duration they are cached. Multiple bean instances that refer to the same database row in a table can be cached. The EJB container maintains a cache for each bean that is deployed.
To achieve scalability, the container selectively evicts some bean instances from the cache, usually when it overflows. These evicted bean instances return to the free bean pool. The size and behavior of each cache can be controlled using the cache-related properties in the EJB container or the glassfish-ejb-jar.xml file.
Pooling and caching parameters for the glassfish-ejb-jar.xml file are described in "bean-cache" in the Payara Server Application Deployment section.
Pooling Parameters
One of the most important parameters for Payara Server pooling is steady-pool-size. When steady-pool-size is set to a value greater than 0, the container not only pre-populates the bean pool with the specified number of beans, but also attempts to ensure that this number of beans is always available in the free pool. This ensures that there are enough beans in the ready-to-serve state to process user requests.
Note that the steady-pool-size and max-pool-size parameters only govern the number of instances that are pooled over a long period of time. They do not necessarily guarantee that the number of instances that may exist in the JVM at a given time will not exceed the value specified by max-pool-size.
For example, suppose an idle stateless session container has a fully-populated pool with a steady-pool-size of 10. If 20 concurrent requests arrive for the EJB component, the container creates 10 additional instances to satisfy the burst of requests. The advantage of this is that it prevents the container from blocking any of the incoming requests. However, if the activity dies down to 10 or fewer concurrent requests, the additional 10 instances are discarded.
Another parameter, pool-idle-timeout-in-seconds, allows the administrator to specify the amount of time a bean instance can be idle in the pool. When pool-idle-timeout-in-seconds is set to greater than 0, the container removes or destroys any bean instance that is idle for this specified duration.
Caching Parameters
Payara Server provides a way that completely avoids caching of entity beans, using commit option C. Commit option C is particularly useful if beans are accessed in large number but very rarely reused. For additional information, refer to Commit Options.
Payara Server caches can be either bounded or unbounded. Bounded caches have limits on the number of beans that they can hold beyond which beans are passivated. For stateful session beans, there are three ways (LRU, NRU and FIFO) of picking victim beans when cache overflow occurs.
Caches can also passivate beans that are idle (not accessed for a specified duration).
Priority Based Scheduling of Remote Bean Invocations
You can create multiple thread pools, each having its own work queues.
An optional element in the glassfish-ejb-jar.xml file, use-thread-pool-id, specifies the thread pool that processes the requests for the bean.
The bean must have a remote interface, or use-thread-pool-id is ignored. You can create different thread pools and specify the appropriate thread pool ID for a bean that requires a quick response time.
| If there is no such thread pool configured or if the element is absent, the default thread pool is used. |
Immediate Flushing
Normally, all entity bean updates within a transaction are batched and executed at the end of the transaction. The only exception is the database flush that precedes execution of a finder or select query.
Since a transaction often spans many method calls, you might want to find out if the updates made by a method succeeded or failed immediately after method execution. To force a flush at the end of a method’s execution, use the flush-at-end-of-method element in the glassfish-ejb-jar.xml file.
Only non-finder methods in an entity bean can be flush-enabled. (For an EJB 2.1 bean, these methods must be in the Local, Local Home, Remote, or Remote Home interface).
See "flush-at-end-of-method" in the Payara Server Application Deployment section.
Upon completion of the method, the EJB container updates the database. Any exception thrown by the underlying data store is wrapped as follows:
-
If the method that triggered the flush is a
createmethod, the exception is wrapped withCreateException. -
If the method that triggered the flush is a
removemethod, the exception is wrapped withRemoveException. -
For all other methods, the exception is wrapped with
EJBException.
All normal end-of-transaction database synchronization steps occur regardless of whether the database has been flushed during the transaction.
EJB Timer Service
The EJB Timer Service uses a database to store persistent information about EJB timers. The EJB Timer Service in Payara Server is preconfigured to use an embedded version of the H2 database via its jdbc/__TimerPool default datasource.
The EJB Timer Service configuration can store persistent timer information in any database supported by Payara Server for persistence. For configurations of supported drivers, see "Configuration Specifics for JDBC Drivers" in the Payara Server General Administration section.
The timer service is automatically enabled when you deploy an application or module that uses it. You can verify that the timer service is running by accessing the following URL in a local context:
http://localhost:8080/ejb-timer-service-app/timerTo change the database used by the EJB Timer Service, set the EJB Timer Service’s Timer DataSource setting to a valid JDBC resource.
If the EJB Timer Service has already been started in a server instance, you must also create the timer database table. DDL files to create these tables are located in as-install/lib/install/databases.
Using the EJB Timer Service is equivalent to interacting with a single JDBC resource manager. If an EJB component or application accesses a database either directly through JDBC or indirectly (for example, through an entity bean’s persistence mechanism), and also interacts with the EJB Timer Service, its data source must be configured with an XA-compatible JDBC driver.
You can change the following EJB Timer Service settings. You must restart the server for these changes to take effect.
- Minimum Delivery Interval
-
Specifies the minimum time in milliseconds before an expiration for a particular timer can occur. This guards against tiny timer increments that can overload the server. The default value is
1000. - Maximum Redeliveries
-
Specifies the maximum number of times the EJB timer service attempts to redeliver a timer expiration after an exception or rollback of a container-managed transaction. The default value is
1. - Redelivery Interval
-
Specifies how long in milliseconds the EJB timer service waits after a failed
ejbTimeoutdelivery before attempting a redelivery. The default is5000. - Timer DataSource
-
Specifies the database used by the EJB Timer Service. The default is
jdbc/__TimerPool.Do not use the jdbc/TimerPoolresource for timers in clustered Payara Server environments. You must instead use a custom JDBC resource or thejdbc/defaultresource. See the instructions below, in To Deploy an EJB Timer to a Cluster.
Also refer to "Enabling the jdbc/default Resource in a Clustered Environment" in the Payara Server General Administration section.
For information about migrating EJB timers, see "Migrating EJB Timers" in the Payara Server High Availability section.
You can use the --keepstate option of the asadmin redeploy command to retain EJB timers between re-deployments.
The default value for --keepstate is false. This option is supported only on the default server instance (the DAS), named server. It is not supported and ignored for any other deployment target.
When the --keepstate is set to true, each application that uses an EJB timer is assigned an ID in the timer database.
The EJB object that is associated with a given application is assigned an ID that is constructed from the application ID and a numerical suffix. To preserve active timer data, Payara Server stores the application ID and the EJB ID in the timer database. To restore the data, the class loader of the newly redeployed application retrieves the EJB timers that correspond to these IDs from the timer database.
Advanced Persistent Timer Configuration
If using an external RDBMS engine for storing persistent timer data is not an option, it is also possible to use the Domain Data Grid to function as a replacement in production environments.
Persisting an EJB Timer to the Domain Data Grid means that the Data Grid itself will store the timer details, preserving it even if the original instance leaves the grid.
|
All stored timers are lost if the whole domain is stopped. In the case of Payara Micro, this will occur if all instances in the Data Grid are stopped as well. |
The Persistence service for EJB Timers can be set in the Admin console by navigating to the EJB Timer Service tab in the EJB Container node of a configuration.
To use the Data Grid to store EJB Timers set the Persistence Service to DataGrid
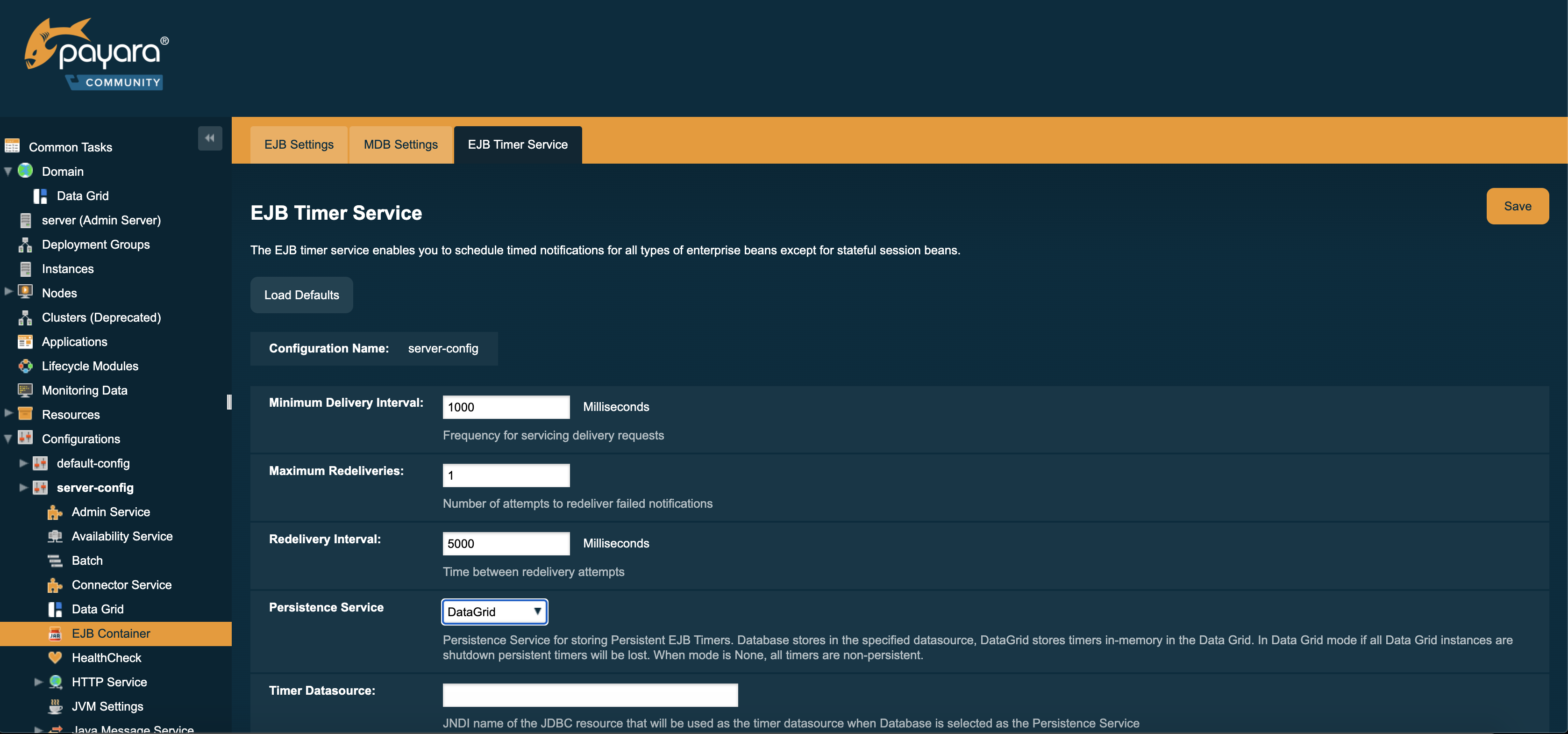
EJB Timers will be coordinated across a single deployment group and if an instance of the deployment group is stopped another instance in the same deployment group will take ownership of the timer and ensure it is fired.
| Clustered Timer Firing Mode is NOT used in this version of Payara Server and is always "One Per Deployment Group" |
It is also possible to set the ejb-timer-service from the command line. To get the current state, run the following command:
asadmin> get configs.config.<your-config>.ejb-container.ejb-timer-serviceThis will return the current state taken from the domain.xml configuration file, which by default should be something similar to the following:
asadmin> get configs.config.server-config.ejb-container.ejb-timer-service
configs.config.server-config.ejb-container.ejb-timer-service.ejb-timer-service=Database
configs.config.server-config.ejb-container.ejb-timer-service.max-redeliveries=1
configs.config.server-config.ejb-container.ejb-timer-service.minimum-delivery-interval-in-millis=1000
configs.config.server-config.ejb-container.ejb-timer-service.redelivery-interval-internal-in-millis=5000
Command get executed successfully.To persist to the Data Grid you need only change the value for configs.config.server-config.ejb-container.ejb-timer-service.ejb-timer-service to DataGrid.
To do this, run the following set command:
asadmin> set configs.config.server-config.ejb-container.ejb-timer-service.ejb-timer-service=DataGrid| You will need to restart your domain to apply the changes. |
Timer Migration
EJB Timers stored in the Domain Data Grid support timer migration between instances in the same Deployment Group. You can migrate timers using the Admin console from the Deployment Group page.
Timers can also be migrated between instances using asadmin commands like this:
asadmin> migrate-timers --target server1 server2Where server1 is the active instance to migrate timers to and server2 is the failed instance.
To Deploy an EJB Timer to a Cluster
This procedure explains how to deploy an EJB timer to a cluster or deployment group.
By default, Payara Server’s Timer Service points to the preconfigured jdbc/__TimerPool resource, which uses an embedded H2 database configuration that will not work in clustered environments.
The problem is that the embedded H2 database runs in the server’s JVM, so when you use the jdbc/__TimerPool resource, each DAS and each server instance will have their own, separate, databases.
Because of this, clustered server instances will not be able to find the database table on the DAS, and the DAS will not be able to find the tables on the clustered server instances.
The solution is to use either a custom JDBC resource or the
jdbc/__default resource that is preconfigured but not enabled by default in Payara Server.
| If you intend on creating a new timer data resource, it should be created BEFORE deploying applications that will use the timer. |
Here are the steps on configuring the Timer Service:
-
Execute the following command:
asadmin set configs.config.cluster_name-config.ejb-container.ejb-timer-service.timer-datasource=jdbc/my-timer-resource -
Restart the DAS and the target cluster(s) or deployment groups.
asadmin stop-cluster cluster-name | deployment-group-name asadmin stop-domain domain-name asadmin start-domain domain-name asadmin start-cluster cluster-name | deployment-group-name
Troubleshooting
If you inadvertently used the jdbc/__TimerPool resource for your EJB timer in a clustered Payara Server environment, the DAS and the server instances will be using separate H2 database instances that are running in individual JVMs.
For timers to work in a clustered environment, the DAS and the clustered server instances must share a common database.
If you attempt to deploy an application with EJB timers without setting the timer resource correctly, the startup will fail, and you will be left with a marker file, named ejb-timer-service-app, on the DAS that will prevent the Timer Service from correctly creating the database table.
The solution is to remove the marker file on the DAS, restart the DAS and the clusters or deployment groups, and then redeploy any applications that rely on the offending EJB timer.
The marker file is located on the DAS in domain-dir/generated/ejb/ejb-timer-service-app.
Using Session Beans
This section provides guidelines for creating session beans in a Payara Server environment.
Information on session beans is contained in the Jakarta Enterprise Beans specification.
About the Session Bean Containers
Like an entity bean, a session bean can access a database through Java Database Connectivity (JDBC) calls. A session bean can also provide transaction settings. These transaction settings and JDBC calls are referenced by the session bean’s container, allowing it to participate in transactions managed by the container.
A container managing stateless session beans has a different charter from a container managing stateful session beans.
Stateless Container
The stateless container manages stateless session beans, which, by definition, do not carry client-specific states. All session beans (of a particular type) are considered equal.
A stateless session bean container uses a bean pool to service requests. The Payara Server specific deployment descriptor file, glassfish-ejb-jar.xml, contains the properties that define the pool:
-
steady-pool-size -
resize-quantity -
max-pool-size -
max-wait-time-in-millis -
pool-idle-timeout-in-seconds
For more information about glassfish-ejb-jar.xml, see "The glassfish-ejb-jar.xml File" in the Payara Server Application Deployment section.
Payara Server provides the wscompile and wsdeploy tools to help you implement a web service endpoint as a stateless session bean.
It is possible to limit the number of concurrent Stateless EJB instances that are dispatched, allowing fine-grained control of resources, limiting surface area for DDOS attacks and making applications run more smoothly and efficiently.
This is done regardless of the maximum number of instances available in a bean’s pool. Using these boundaries, it is possible to instruct the EJB container so that the maximum number of threads is not exceeded at runtime.
The system property fish.payara.ejb-container.max-wait-time-in-millis can be set to change the default global value of <max-wait-time-in-millis> for ALL Stateless EJB bean pools.
|
| Unless overridden in the deployment descriptor file, this will become the new default value and can be used to cap the upper bound of all concurrent invocations of any Stateless EJB pools. |
Example
The following is a sample glassfish-ejb-jar.xml deployment descriptor that configures 2 EJBs with the settings mentioned beforehand.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE glassfish-ejb-jar PUBLIC "-//GlassFish.org//DTD GlassFish Application Server 3.1 EJB 3.1//EN" "http://glassfish.org/dtds/glassfish-ejb-jar_3_1-1.dtd">
<glassfish-ejb-jar>
<enterprise-beans>
<ejb>
<ejb-name>PooledStatelessBean</ejb-name>
<bean-pool>
<max-pool-size>1</max-pool-size>
<max-wait-time-in-millis>0</max-wait-time-in-millis>
<steady-pool-size>1</steady-pool-size>
</bean-pool>
</ejb>
<ejb>
<ejb-name>PooledMDB</ejb-name>
<bean-pool>
<max-pool-size>1</max-pool-size>
<resize-quantity>1</resize-quantity>
</bean-pool>
</ejb>
</enterprise-beans>
</glassfish-ejb-jar>Stateful Container
The stateful container manages the stateful session beans, which, by definition, carry the client-specific state. There is a one-to-one relationship between the client and the stateful session beans. At creation, each stateful session bean (SFSB) is given a unique session ID that is used to access the session bean so that an instance of a stateful session bean is accessed by a single client only.
Stateful session beans are managed using an internal cache. The size and behavior of stateful session beans cache are controlled by specifying the following glassfish-ejb-jar.xml parameters:
-
max-cache-size -
resize-quantity -
cache-idle-timeout-in-seconds -
removal-timeout-in-seconds -
victim-selection-policy
The max-cache-size element specifies the maximum number of session beans that are held in cache. If the cache overflows (when the number of beans exceeds max-cache-size), the container then passivates some beans or writes out the serialized state of the bean into a file. The directory in which the file is created is obtained from the EJB container using the configuration APIs.
For more information about glassfish-ejb-jar.xml, see "The glassfish-ejb-jar.xml File" in the Payara Server Application Deployment section.
The passivated beans are stored on the file system. The Session Store Location setting in the EJB container allows an administrator to specify the directory where passivated beans are stored. By default, passivated stateful session beans are stored in application-specific subdirectories created under ${domain-dir}/session-store.
Make sure the delete option is set in the server.policy file, or expired file-based sessions might not be deleted properly.
For more information about server.policy, see The server.policy File.
|
The Session Store Location setting also determines where the session state is persisted if it is in a High Availability environment; see Choosing a Persistence Store.
Stateful Session Bean Failover
A stateful session bean’s state can be saved in a persistent store in case a server instance fails. The state of an SFSB is saved to the persistent store at predefined points in its life cycle. This is called checkpointing. If SFSB checkpointing is enabled, checkpointing generally occurs after any transaction involving the SFSB is completed, even if the transaction rolls back.
However, if an SFSB participates in a bean-managed transaction, the transaction might be committed in the middle of the execution of a bean method. Since the bean’s state might be undergoing transition as a result of the method invocation, this is not an appropriate instant to checkpoint the bean’s state.
In this case, the EJB container checkpoints the bean’s state at the end of the corresponding method, provided the bean is not in the scope of another transaction when that method ends. If a bean-managed transaction spans across multiple methods, checkpointing is delayed until there is no active transaction at the end of a subsequent method.
The state of an SFSB is not necessarily transactional and might be significantly modified as a result of non-transactional business methods. If this is the case for an SFSB, you can specify a list of checkpointed methods. If SFSB checkpointing is enabled, checkpointing occurs after any checkpointed methods are completed.
The following table lists the types of references that SFSB failover supports.
All objects bound into an SFSB must be one of the supported types. In the table, No indicates that failover for the object type might not work in all cases and that no failover support is provided.
However, failover might work in some cases for that specific object type.
For example, failover might work because the class implementing that type is serializable.
| Java Object Type | Failover Support |
|---|---|
Co-located or distributed stateless session, stateful session, or entity bean reference |
Yes |
JNDI context |
Yes, |
|
Yes, but if the instance that fails is never restarted, any prepared global transactions are lost and might not be correctly rolled back or committed. |
JDBC DataSource |
No |
Java Message Service (JMS) ConnectionFactory, Destination |
No |
JavaMail Session |
No |
Connection Factory |
No |
Administered Object |
No |
Web service reference |
No |
Serializable Java types |
Yes |
Extended persistence context |
No |
For more information about the InitialContext, see
Accessing the Naming Context. For more information about transaction recovery, see Using the Transaction Service. For more information about Administered Objects, see "Administering JMS Physical Destinations" in the Payara Server General Administration section.
If a server instance to which an RMI-IIOP client request is sent crashes during the request processing (before the response is prepared and sent back to the client), an error is sent to the client.
The client must retry the request explicitly. When the client retries the request, the request is sent to another server instance in the cluster, which retrieves session state information for this client.
HTTP sessions can also be saved in a persistent store in case a server instance fails. In addition, if a distributable web application references an SFSB, and the web application’s session fails over, the EJB reference is also failed over. For more information, see Distributed Sessions and Persistence.
If an SFSB that uses session persistence is un-deployed while the Payara Server instance is stopped, the session data in the persistence store might not be cleared. To prevent this, undeploy the SFSB while the Payara Server instance is running.
Configure SFSB failover by:
-
Choosing a Persistence Store
-
Enabling Checkpointing
-
Specifying Methods to Be Checkpointed
Choosing a Persistence Store
The following types of persistent storage are supported for passivation and checkpointing of the SFSB state:
- The local file system
-
Allows a single server instance to recover the SFSB state after a failure and restart. This store also provides passivation and activation of the state to help control the amount of memory used. This option is not supported in a production environment that requires SFSB state persistence.
This is the default storage mechanism if availability is not enabled. - Other servers
-
Uses other server instances in the cluster for session persistence. Clustered server instances replicate session state. Each backup instance stores the replicated data in memory. This is the default storage mechanism if availability is enabled.
Choose the persistence store in one of the following ways:
-
To use the local file system, first disable availability. Select the Availability Service component under the relevant configuration in the Administration Console. Uncheck the Availability Service box. Then select the EJB Container component and edit the Session Store Location value. The default is
${domain-dir}/session-store. -
To use other servers, select the Availability Service component under the relevant configuration in the Administration Console. Check the Availability Service box. To enable availability for the EJB container, select the EJB Container Availability tab, then check the Availability Service box.
All instances in a Payara Server cluster or deployment group must have the same availability settings to ensure consistent behavior.
Using the --keepstate Option
If you are using the file system for persistence, you can use the --keepstate option of the asadmin redeploy command to retain the SFSB state between re-deployments.
The default value for --keepstate is false. This option is supported only on the default server instance (the DAS), named server. It is not supported and ignored for any other deployment target.
Some changes to an application between re-deployments prevent this feature from working properly. For example, do not change the set of instance variables in the SFSB bean class.
If any active SFSB instance fails to be preserved or restored, none of the SFSB instances will be available when the redeployment is complete. However, the redeployment continues and a warning is logged.
To preserve active state data, Payara Server serializes the data and saves it in memory. To restore the data, the class loader of the newly redeployed application deserializes the data that was previously saved.
Using the --asyncreplication Option
If you are using replication on other servers for persistence, you can use the --asyncreplication option of the asadmin deploy command to specify that SFSB states are first buffered and then replicated using a separate asynchronous thread.
If --asyncreplication is set to true (the default), performance is improved but availability is reduced. If the instance where states are buffered but not yet replicated fails, the states will be lost.
If set to false, performance is reduced but availability is guaranteed. States are not buffered but immediately transmitted to other instances in the cluster or deployment group.
Enabling Checkpointing
Server Instance and EJB Container Levels
To enable SFSB checkpointing at the server instance or EJB container level, see Choosing a Persistence Store.
Application and EJB Module Levels
To enable SFSB checkpointing at the application or EJB module level during deployment, use the asadmin deploy or asadmin deploydir command with the --availabilityenabled option set to true.
SFSB Level
To enable SFSB checkpointing at the bean level, set availability-enabled="true" in the ejb element of the bean definition in the glassfish-ejb-jar.xml file as follows:
<glassfish-ejb-jar>
...
<enterprise-beans>
...
<ejb availability-enabled="true">
<ejb-name>MySFSB</ejb-name>
</ejb>
...
</enterprise-beans>
</glassfish-ejb-jar>Specifying Methods to Be Checkpointed
If SFSB checkpointing is enabled, checkpointing generally occurs after any transaction involving the SFSB is completed, even if the transaction rolls back.
To specify additional optional checkpointing of SFSBs at the end of non-transactional business methods that cause important modifications to the bean’s state, use the checkpoint-at-end-of-method element within the ejb element in glassfish-ejb-jar.xml.
For example:
<glassfish-ejb-jar>
...
<enterprise-beans>
...
<ejb availability-enabled="true">
<ejb-name>ShoppingCartEJB</ejb-name>
<checkpoint-at-end-of-method>
<method>
<method-name>addToCart</method-name>
</method>
</checkpoint-at-end-of-method>
</ejb>
...
</enterprise-beans>
</glassfish-ejb-jar>For details, see "checkpoint-at-end-of-method" in the Payara Server Application Deployment section.
The non-transactional methods in the checkpoint-at-end-of-method element can be the following:
-
createmethods defined in the home or business interface of the SFSB, if you want to checkpoint the initial state of the SFSB immediately after creation. -
For SFSBs using container managed transactions only, methods in the remote interface of the bean marked with the transaction attribute
TX_NOT_SUPPORTEDorTX_NEVER. -
For SFSBs using bean managed transactions only, methods in which a bean managed transaction is neither started nor committed.
Any other methods mentioned in this list are ignored. At the end of invocation of each of these methods, the EJB container saves the state of the SFSB to the persistent store.
If an SFSB does not participate in any transaction, and if none of its methods are explicitly specified in the checkpoint-at-end-of-method element, the bean’s state is not checkpointed at all even if availability-enabled="true" for this bean.
|
For better performance, specify a small subset of methods. The methods chosen should accomplish a significant amount of work in the context of the Jakarta EE application or should result in some important modification to the bean’s state.
Session Bean Restrictions and Optimizations
This section discusses restrictions on developing session beans and provides some optimization guidelines.
Optimizing Session Bean Performance
For stateful session beans, co-locating the stateful beans with their clients so that the client and bean are executing in the same process address space improves performance.
Restricting Transactions
The following restrictions on transactions are enforced by the container and must be observed as session beans are developed:
-
A session bean can participate in, at most, a single transaction at a time.
-
If a session bean is participating in a transaction, a client cannot invoke a method on the bean such that the
trans-attributeelement (or@TransactionAttributeannotation) in theejb-jar.xmlfile would cause the container to execute the method in a different or unspecified transaction context or an exception is thrown. -
If a session bean instance is participating in a transaction, a client cannot invoke the
removemethod on the session object’s home or business interface object, or an exception is thrown.
Using Read-Only Beans
A read-only bean is an EJB 2.1 entity bean that is never modified by an EJB client. The data that a read-only bean represents can be updated externally by other enterprise beans, or by other means, such as direct database updates.
| Read-only beans are specific to Payara Server and are not part of the Jakarta Enterprise Beans Specification. Use of this feature for an EJB 2.1 bean results in a non-portable application. |
To make an EJB 3.0+ entity bean read-only, use @Column annotations to mark its columns insertable=false and updatable=false.
|
Read-only beans are best suited for situations where the underlying data never changes, or changes infrequently.
Read-Only Bean Characteristics and Life Cycle
Read-only beans are best suited for situations where the underlying data never changes, or changes infrequently. For example, a read-only bean can be used to represent a stock quote for a particular company, which is updated externally. In such a case, using a regular entity bean might incur the burden of calling ejbStore, which can be avoided by using a read-only bean.
Read-only beans have the following characteristics:
-
Only entity beans can be read-only beans.
-
Either bean-managed persistence (BMP) or container-managed persistence (CMP) is allowed. If CMP is used, do not create the database schema during deployment. Instead, work with your database administrator to populate the data into the tables. See Using Container-Managed Persistence.
-
Only container-managed transactions are allowed; read-only beans cannot start their own transactions.
-
Read-only beans don’t update any bean state.
-
ejbStoreis never called by the container. -
ejbLoadis called only when a transactional method is called or when the bean is initially created (in the cache), or at regular intervals controlled by the bean’srefresh-period-in-secondselement in theglassfish-ejb-jar.xmlfile. -
The home interface can have any number of find methods. The return type of the find methods must be the primary key for the same bean type (or a collection of primary keys).
-
If the data that the bean represents can change, then
refresh-period-in-secondsmust be set to refresh the beans at regular intervals.ejbLoadis called at this regular interval.
A read-only bean comes into existence using the appropriate find methods.
Read-only beans are cached and have the same cache properties as entity beans.
When a read-only bean is selected as a "victim" to make room in the cache, ejbPassivate is called and the bean is returned to the free pool.
When in the free pool, the bean has no identity and is used only to serve any finder requests.
Read-only beans are bound to the naming service like regular read-write entity beans, and clients can look up read-only beans the same way read-write entity beans are looked up.
Read-Only Bean Good Practices
For best results, follow these guidelines when developing read-only beans:
-
Avoid having any
createorremovemethods in the home interface. -
Use any of the valid EJB 2.1 transaction attributes for the
trans-attributeelement.The reason for having
TX_SUPPORTEDis to allow reading uncommitted data in the same transaction. Also, the transaction attributes can be used to forceejbLoad.
Refreshing Read-Only Beans
There are several ways of refreshing read-only beans, as addressed in the following sections:
Refreshing Periodically
Use the refresh-period-in-seconds element in the glassfish-ejb-jar.xml file to refresh a read-only bean periodically.
-
If the value specified in
refresh-period-in-secondsis zero or not specified, which is the default, the bean is never refreshed (unless a transactional method is accessed). -
If the value is greater than zero, the bean is refreshed at the rate specified.
| This is the only way to refresh the bean state if the data can be modified external to Payara Server. |
By default, a single timer is used for all instances of a read-only bean. When that timer fires, all bean instances are marked as expired and are refreshed from the database the next time they are used.
Use the -Dcom.sun.ejb.containers.readonly.relative.refresh.mode=true flag to refresh each bean instance independently upon access if its refresh period has expired. Its default value is false. Note that each instance still has the same refresh period.This additional level of granularity can improve the performance of read-only beans that do not need to be refreshed at the same time.
To set this flag, use the asadmin create-jvm-options command. For example:
asadmin create-jvm-options -Dcom.sun.ejb.containers.readonly.relative.refresh.mode=trueRefreshing Programmatically
Typically, beans that update any data that is cached by read-only beans need to notify the read-only beans to refresh their state. Use the ReadOnlyBeanNotifier interface to force the refresh of read-only beans.
To do this, invoke the following methods on the ReadOnlyBeanNotifier bean:
public interface ReadOnlyBeanNotifier extends java.rmi.Remote {
refresh(Object PrimaryKey) throws RemoteException;
}The implementation of the ReadOnlyBeanNotifier interface is provided by the container. The bean looks up ReadOnlyBeanNotifier using a fragment of code such as the following example:
public class MyEJB{
public void execute(){
var helper = new com.sun.appserv.ejb.ReadOnlyBeanHelper();
var notifier = helper.getReadOnlyBeanNotifier("java:comp/env/ejb/ReadOnlyCustomer");
//Assume entity is a CMP entity bean
notifier.refresh(entity);
}
}For a local read-only bean notifier, the lookup has this modification:
public class MyEJB{
public void execute(){
var helper = new com.sun.appserv.ejb.ReadOnlyBeanHelper();
var notifier = helper.getReadOnlyBeanNotifier("java:comp/env/ejb/LocalReadOnlyCustomer");
//Assume entity is a CMP entity bean
notifier.refresh(entity);
}
}Beans that update any data that is cached by read-only beans need to call the refresh methods. The next (non-transactional) call to the read-only bean invokes ejbLoad.
Deploying Read-Only Beans
Read-only beans are deployed in the same manner as other entity beans. However, in the entry for the bean in the glassfish-ejb-jar.xml file, the is-read-only-bean element must be set to true. That is:
<is-read-only-bean>true</is-read-only-bean>Also, the refresh-period-in-seconds element in the glassfish-ejb-jar.xml file can be set to some value that specifies the rate at which the bean is refreshed. If this element is missing, no refresh occurs.
All requests in the same transaction context are routed to the same read-only bean instance. Set the allow-concurrent-access element to
either true (to allow concurrent accesses) or false (to serialize concurrent access to the same read-only bean). The default is false.
For further information on these elements, refer to "The glassfish-ejb-jar.xml File" in the Payara Server Application Deployment section.
Using Message-Driven Beans
This section describes message-driven beans and explains the requirements for creating them in a Payara Server environment.
Message-Driven Bean Configuration
For information about setting up load balancing for message-driven beans, see Load-Balanced Message Inflow.
Connection Factory and Destination
A message-driven bean is a client to a Connector inbound resource adapter. The message-driven bean container uses the JMS service integrated into Payara Server for message-driven beans that are JMS clients. JMS clients use JMS Connection Factory- and Destination-administered objects. A JMS Connection Factory administered object is a resource manager Connection Factory object that is used to create connections to the JMS provider.
The mdb-connection-factory element in the glassfish-ejb-jar.xml file for a message-driven bean specifies the connection factory that creates the container connection to the JMS provider.
The jndi-name element of the ejb element in the glassfish-ejb-jar.xml file specifies the JNDI name of the administered object for the JMS Queue or Topic destination that is associated with the message-driven bean.
Message-Driven Bean Pool
The container manages a pool of message-driven beans for the concurrent processing of a stream of messages. The glassfish-ejb-jar.xml file contains the elements that define the pool (that is, the bean-pool element):
-
steady-pool-size -
resize-quantity -
max-pool-size -
pool-idle-timeout-in-seconds
For more information about glassfish-ejb-jar.xml, see "The glassfish-ejb-jar.xml File" in the Payara Server Application Deployment section.
Domain-Level Settings
You can control the following domain-level message-driven bean settings in the EJB container:
- Initial and Minimum Pool Size
-
Specifies the initial and minimum number of beans maintained in the pool. The default is
0. - Maximum Pool Size
-
Specifies the maximum number of beans that can be created to satisfy client requests. The default is
32. - Pool Resize Quantity
-
Specifies the number of beans to be created if a request arrives when the pool is empty (subject to the Initial and Minimum Pool Size), or the number of beans to remove if idle for more than the Idle Timeout. The default is
8. - Idle Timeout
-
Specifies the maximum time in seconds that a bean can remain idle in the pool. After this amount of time, the bean is destroyed. The default is
600(10 minutes). A value of0means a bean can remain idle indefinitely.
Select the Instances component, select the instance from the table, and select the Monitor tab.
| Running monitoring when it is not needed might impact performance, so you might choose to turn monitoring off when it is not in use. For details, see "Administering the Monitoring Service" in the Payara Server General Administration section. |
Message-Driven Bean Restrictions and Optimizations
This section discusses the following restrictions and performance optimizations that pertain to developing message-driven beans:
Pool Tuning and Monitoring
The message-driven bean pool is also a pool of threads, with each message-driven bean instance in the pool associating with a server session, and each server session associating with a thread.
Therefore, a large pool size also means a high number of threads, which impacts performance and server resources.
When configuring message-driven bean pool properties, make sure to consider factors such as message arrival rate and pattern, onMessage method processing time, overall server resources (threads, memory, and so on), and any concurrency requirements and limitations from other resources that the message-driven bean accesses.
When tuning performance and resource usage, make sure to consider potential JMS provider properties for the connection factory used by the container (the mdb-connection-factory element in the glassfish-ejb-jar.xml file). For example, you can tune the Open Message Queue flow control related properties for connection factory in situations where the message incoming rate is much higher than max-pool-size can handle.
Refer to "Administering the Monitoring Service" in the Payara Server General Administration section for information on how to get message-driven bean pool statistics.
Fine-tuning with the ActivationConfigProperty annotation
It is also possible to configure the MDB bean pool size with the ActivationConfigProperty annotation. Any bean annotated with @MessageDriven can use @ActivationConfigProperty to set property names and property values. For example:
@ActivationConfigProperty(propertyName = "MaxPoolSize", propertyValue = "100")
public class CustomerListener implements MessageListener{
}The MaxPoolSize, MaxWaitTimeInMillis, PoolResizeQuantity, SteadyPoolSize and PoolIdleTimeoutInSeconds are all MDB pool properties that can configured using the @ActivationConfigProperty annotation.
The onMessage Runtime Exception
Message-driven beans, like other well-behaved MessageListener implementations, should not, in general, throw runtime exceptions.
If a message-driven bean’s onMessage method encounters a system-level exception or error that does not allow the method to successfully complete, the Jakarta Enterprise Beans Specification provides the following guidelines:
-
If the bean method encounters a system exception or error, it should simply propagate the error from the bean method to the container (i.e., the bean method does not have to catch the exception).
-
If the bean method performs an operation that results in a checked exception that the bean method cannot recover, the bean method should throw the
jakarta.ejb.EJBExceptionthat wraps the original exception. -
Any other unexpected error conditions should be reported using the
jakarta.ejb.EJBException.
Under container-managed transaction demarcation, upon receiving a runtime exception from a message-driven bean’s onMessage method,
the container rolls back the container-started transaction and the message is redelivered. This is because the message delivery itself is part of the container-started transaction.
By default, the Payara Server container closes the container’s connection to the JMS provider when the first runtime exception is received from a message-driven bean instance’s onMessage method.
This avoids potential message redelivery looping and protects server resources if the message-driven bean’s onMessage method continues misbehaving. To change this default container behavior, use the cmt-max-runtime-exceptions property of the MDB container.
Here is an example asadmin set command that sets this property:
asadmin set server-config.mdb-container.property.cmt-max-runtime-exceptions="5"The cmt-max-runtime-exceptions property specifies the maximum number of runtime exceptions allowed from a message-driven bean’s onMessage
method before the container starts to close the container’s connection to the message source. By default, this value is set to 1; -1 disables this container protection.
A message-driven bean’s onMessage method can use the jakarta.jms.Message.getJMSRedelivered method to check whether a received message is a redelivered message.
The cmt-max-runtime-exceptions property is deprecated and support for this feature may be removed in the future.
|
EJB Timers in Deployment Groups
| This section only applies to Payara Server environments. |
Timer facilities provided by the EJB APIs TimerService and @Scheduled need special configuration in order to work intuitively for applications targeting a deployment group. It is important to understand how EJB timers run (or expire) when configured on deployment group scenarios.
Before stating the specifics, keep in mind that there are four types of timers distinguished by their lifecycle (persistent, non-persistent) and the means of their definition (declarative, programmatic).
-
Declarative timers are defined in EJB deployment descriptors or with the
@Scheduledannotation. -
Programmatic timers are created via calls to the
TimerService.createTimermethod and its equivalents.
Non-Persistent Timers
Non-Persistent timers exist in memory only for the duration in which the application runs on the instances that belong to a deployment group.
Declarative non-persistent timers run/expire on every instance, whereas programmatic ones only run/expire on the instance that created them. When the instance shuts down, the timer will stop its expiration.
Standalone instances do not see each other’s non-persistent timers, so calling TimerService.getTimers() only returns local non-persistent timers.
Non-Persistent timers have a simpler lifecycle but are not the default option. To explicitly define a non-persistent timer, the @Schedule annotation needs the persistent=false attribute, or the TimerConfig objects need to have their property persistent set to false explicitly.
Persistent Timers
Persistent timers exist in the persistent store for the entire time for which application is deployed to its corresponding domain.
Contrary to non-persistent ones, each persistent timer is only executed on a single instance of a deployment group. When the instance shuts down, each persistent timer migrates to another instance in the application’s deployment group and continues firing there.
Since persistent timers are shared, the TimerService.getTimers() method returns all persistent timers in the deployment group, regardless of which instance created them.
| EJB Timers are persistent by default. |
Preconditions for using Persistent Timers in Deployment Groups
Because deployment groups do not need to share configurations amongst their instances, there are several configuration and operational constraints that are not enforced by the server.
To ensure correct behaviour of persistent timers within a deployment group, the following conditions need to be met:
-
The EJB Timer Service needs to use shared storage --an external database-- or the DataGrid.
-
All instances of a deployment group, and the Domain Administration Server MUST share the same configuration settings for the EJB Timer Service (see here for more information).
-
Applications with persistent timers are deployed to a deployment group and not managed on instance level afterward.
-
Instances are members of only a single deployment group
EJB Timers may behave in unexpected ways if these conditions are not met.
Tracing Remote EJBs
Remote calls to an EJB from a Java SE client will have their active OpenTracing span context automatically propagated to the server, with the server-side span being created as a child of this client call. This will allow users to trace EJB calls that are originated externally from the server, and the span context will be propagated internally to any traceable components.
Java SE Client Tracing
No additional setup is required on the client side over what is to be expected for making regular un-traced remote EJB calls - the requirements are the same: usage of payara-embedded-all or the application client facilities of a Payara Server instance.
No additional properties need to be specified when performing the initial context lookup either:
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.util.Properties;
public class MainClass{
public static void main(String[] args){
var contextProperties = new Properties();
contextProperties.setProperty(Context.INITIAL_CONTEXT_FACTORY, "com.sun.enterprise.naming.SerialInitContextFactory");
try {
Context context = new InitialContext(contextProperties);
EjbRemote ejb = (EjbRemote) context.lookup("java:global/myRemoteEjb/Ejb");
} catch (NamingException ne) {
logger.warning("Failed performing lookup:\n" + ne.getMessage());
}
}
}Getting a Tracer Instance
Injection of an OpenTracing tracer is not supported on Java SE clients, so you must create an instance yourself and register it to a GlobalTracer instance.
| Manual registration of a tracer instance is only required if using a third-party tracer such as ZipKin or Jaeger - if using the built-in Payara Platform Request Tracing service the registration will automatically happen during creation of the initial context. |
|
The built-in Payara Request Tracing service does not support tracing of Java SE clients (though will still propagate the active span context to the server) If you wish to trace the client itself you must set up and use a third-party tracer such as ZipKin or Jaeger. Details on setting these up can be found here. |
import io.opentracing.Tracer;
import io.opentracing.util.GlobalTracer;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.util.Properties;
public class MainClass{
public static void main(String[] args){
var contextProperties = new Properties();
contextProperties.setProperty(Context.INITIAL_CONTEXT_FACTORY, "com.sun.enterprise.naming.SerialInitContextFactory");
try {
Context context = new InitialContext(contextProperties);
EjbRemote ejb = (EjbRemote) context.lookup("java:global/myRemoteEjb/Ejb");
Tracer tracer = GlobalTracer.get();
} catch (NamingException ne) {
logger.warning("Failed performing lookup:\n" + ne.getMessage());
}
}
}Extra information on creating a Tracer instance and registering it to the GlobalTracer can be found here, but in short it can be done like so (replacing CustomTracer with your desired implementation):
public class MainClass{
public static void main(String[] args){
Tracer tracerImpl = new CustomTracer();
GlobalTracer.register(tracerImpl);
}
}Starting a Span
The @Traced annotation is not supported on Java SE client methods, so spans must be started and finished manually. Note that the Span Context of the active span will be propagated to the server, so it is recommended that you use a try-with-resources clause to help ensure your span scope is the one you expect.
import io.opentracing.Scope;
import io.opentracing.Span;
import io.opentracing.Tracer;
import io.opentracing.util.GlobalTracer;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.util.Properties;
public class TracerClass{
public static void main(String[] args){
var contextProperties = new Properties();
contextProperties.setProperty(Context.INITIAL_CONTEXT_FACTORY, "com.sun.enterprise.naming.SerialInitContextFactory");
try {
Context context = new InitialContext(contextProperties);
EjbRemote ejb = (EjbRemote) context.lookup("java:global/myRemoteEjb/Ejb");
Tracer tracer = GlobalTracer.get();
try (Scope scope = tracer.buildSpan("ExecuteEjb").startActive(true)) {
ejb.doTheThing();
}
} catch (NamingException ne) {
logger.warning("Failed performing lookup:\n" + ne.getMessage());
}
}
}Once your span has been started, you can attach any desired baggage items (String key:value pairs), and these will be propagated to the server along with the span context. These can then be retrieved within the EJB implementation hosted on Payara Server like so:
import io.opentracing.Span;
import io.opentracing.Tracer;
import jakarta.ejb.Stateless;
import jakarta.inject.Inject;
@Stateless
public class Ejb implements EjbRemote {
@Inject
Tracer tracer;
public void businessMethod(){
Span activeSpan = tracer.activeSpan();
if (activeSpan != null) {
String myBaggageItem = activeSpan.getBaggageItem("myBaggageItem");
}
}
}
Baggage items are attached to the Span you invoke setBaggageItem on, as well as any child spans, so you are not prevented from starting additional child spans on your EJB methods manually or via the @Traced annotation.
|