The Domain Data Grid uses Hazelcast as its clustering technology to provide an in-memory data structure that is distributed amongst all the Payara Server instances within a Payara Domain.
The Data Grid is highly available and highly scalable and enables in-memory data storage and sharing between all Payara Server instances in a domain. The Domain Data Grid is used as the backing store for web session data, Stateful Session Bean state, JCache caches, Clustered Singletons, and Single Sign On state as well as internal Payara domain data like performance metrics and traces. In addition, Persistent EJB Timers can also be configured to be stored in the grid. The Domain Data Grid also enables light-weight messaging between server instances and is the foundation of the CDI Clustered Event Bus.
The Domain Data Grid greatly simplifies traditional clustering as by default it is always on, always available and usually requires no special configuration.
The Domain Data Grid has been designed to work out of the box in a variety of network topologies and usually requires zero configuration in LAN, Amazon AWS, Google Cloud Platform and Microsoft Azure.
The following topics are addressed here:
Domain Data Grid Benefits
High Availability
The Domain Data Grid achieves high availability for data storage by maintaining a replica on another Payara Server Instance of any data placed into the Domain Data Grid. This replica will be placed, as a preference, on an instance that is not running on the same host as the primary data item. If the instance holding the primary copy of a piece of data fails then the backup copy will become the primary and another instance will be selected to hold a back up of the data.
Scalability
The Domain Data Grid provides high scalability for data placed into the Data Grid. As a primary and a secondary copy of any data item placed into the grid the more instances that are added to the Payara Domain the more JVM heap is available for storage of data in the grid. The Domain Data Grid can scale to 10s and 100s of instances allowing large data sets to be stored in memory. Read and Write performance for data in the grid is not dependent on the number of Payara Server instances in the domain providing scalability to grids containing large numbers of Payara Server instances.
Elasticity
The Domain Data Grid does require configuring with a specific number of Payara Server instances. Payara Server and Payara Micro instances can be added and removed and the Data Grid will shrink and grow as required. This meets the needs of cloud and container based architectures which can scale up or scale down the number of Payara instances handling requests.
Payara Micro Interoperability
The Domain Data Grid is designed to be interoperable with Payara Micro and Payara Micro instances can join the Data Grid and store data. Payara Micro has a specific cluster mode which can be enabled to join a Domain Data Grid.
Data Sharing and Encryption
The Domain Data Grid allows multiple Payara Server or Payara Micro instances to join and form a robust cluster of interchangeable nodes that can share and transfer data between applications. Enable encryption and data stored in-memory via the Domain Data Grid will have end-to-end encryption of the data across all instances in the domain. End-to-end encryption is encryption of data both at rest (in storage) and in transit (during communication).
Light-Weight Domain Messaging
Typically, you normally need a ‘system’ between the sender and receiver to transport data from one domain to another and possibly hold that data until receiver is able to process it. The Domain Data Grid is a lightweight messaging transport system, so you don’t need any additional resources and installation of components to send messages within the domain.
Domain Data Grid Discovery Modes
The Domain Data Grid has the concept of auto-discovery. When a Payara Server or Payara Micro instance starts it must discover other Data Grid nodes so that it can join the grid. Once an instance has connected to a Payara Instance that is already a member of the grid then it can become a member of the grid. The below are the discovery mechanisms or modes that are included by default in Payara Server.
Domain Discovery Mode
The Domain discovery mode is the default discovery mode in Payara Server. In this mode when a Payara Server instance starts it uses information encoded into the domain.xml describing the node IP Address and ports of the other servers in the domain and the DAS to connect to an existing member of the Data Grid. For a Payara Server instance the first server it will try to connect to is the DAS if that fails it will then try each of the other instances in turn. When the DAS starts it tries to connect to each instance in turn.
As the domain.xml is used to discover other members of the Data Grid no further user configuration is usually necessary.
|
TCP-IP Discovery Mode
The TCP-IP discovery mode is an alternative discovery mode. In this mode the user specifies a comma separated list of IP addresses and ports that a Payara Server instance should try to find members of the data grid at upon boot.
| This discovery mode can be used to build a topology based on single instances of the DAS joining together to create the Data Grid. This is common in container based topologies with no central domain administration server. |
Multicast Discovery Mode
The Multicast discovery mode is an alternative discovery mode. In this mode the user specifies the multicast group and multicast port used to find other members of the Data Grid. When a Payara Server instance configured with multicast discovery starts it broadcasts a message on the multicast group and port to discover other members of the data grid.
| This discovery mode can be used to also build a topology based on single instances of the DAS joining together to create the data grid. In this mode multicast must be supported on the network. |
| This mode is the default mode for Payara Micro |
| Also change the Data Grid group name and password to prevent other instances on the same LAN inadvertently joining your data grid. |
DNS Discovery Mode
The DNS discovery mode is an alternative discovery mode, closely related to the TCP-IP discovery mode. In this mode the user specifies a comma separated list of DNS names and ports that a Payara Server should try to find members of the data grid at upon boot.
Kubernetes Discovery Mode
The Kubernetes discovery mode is an alternative discovery mode intended for use when running in a Kubernetes environment. In this mode, the user specifies the Kubernetes service name and namespace that Payara Server should look to find other data grid members in - Payara Server will then contact the Kubernetes master upon boot to obtain the list of IP addresses of any other running instances under the specified namespace and service name.
This clustering is done using the Hazelcast Kubernetes plugin, and so you will need to grant Hazelcast permission to query the Kubernetes master node. As per the plugin documentation, you will need to apply the permissions outlined below using kubectl apply.The original documentation on configuring these permissions can be found here, as well as extra documentation on how to restrict these permissions further here. |
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: default-cluster
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: view
subjects:
- kind: ServiceAccount
name: default
namespace: defaultConfiguration Discovery Mode in Administration Console
The domain discovery mode can be configured in the administration console under the Data Grid menu option. The discovery mode that is set gets to be applied in a domain-wide manner.
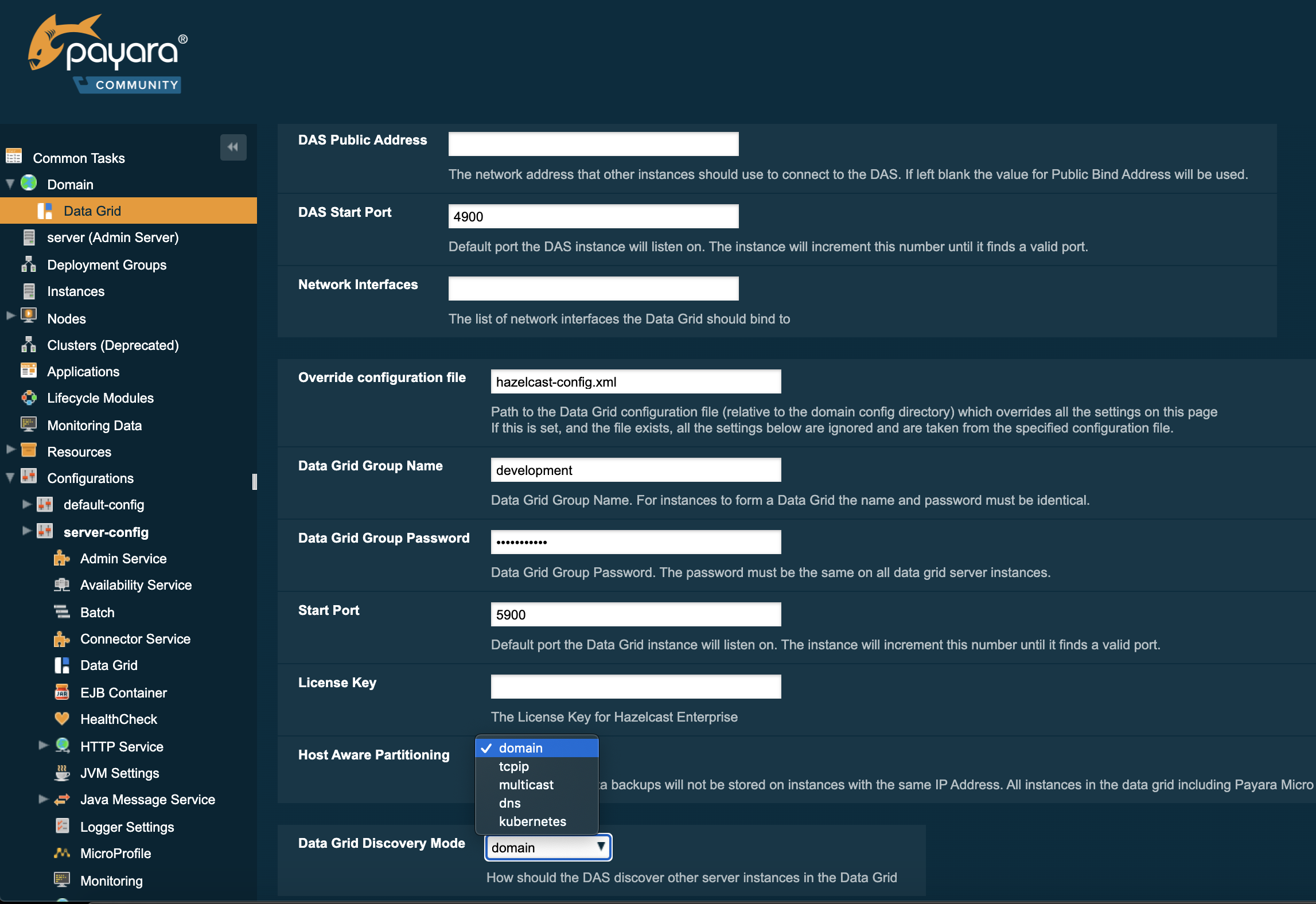
Configuration Discovery Mode via Asadmin CLI
The discovery mode can be set via the asadmin CLI, depending on the specific mode to be selected, by running the set-hazelcast-configuration commands.
Set TCP-IP Mode
When setting TCP-IP mode the list of IP addresses and ports of all Data Grid members must be specified:
asadmin> set-hazelcast-configuration --clustermode tcpip --tcpipmembers 192.168.0.104:4900,192.168.0.105:5900Set Multicast Mode
When setting multicast mode the multicast group and multicast port must be also specified.
If these settings are not specified they will default to 224.2.2.3 and 54327
|
asadmin> set-hazelcast-configuration --clustermode multicast --multicastgroup 224.2.2.4 --multicastport 55000Set DNS Mode
When setting DNS mode the list of DNS names and ports of all Data Grid members must be specified.
asadmin> set-hazelcast-configuration --clustermode dns --dnsmembers localhost:4900,www.example.com:5900Set Kubernetes Mode
When setting Kubernetes mode the service name and namespace must be specified using the --kubernetesservicename and --kubernetesnamespace options respectively.
| If a namespace is not specified, Payara Server will use the "default" namespace. |
asadmin> set-hazelcast-configuration --clustermode kubernetes --kubernetesServiceName payara --kubernetesNamespace defaultEnabling and Disabling the Data Grid
The data grid is enabled by default in Payara Server. It can be disabled and re-enabled either through the Admin Console, or by using a command line asadmin command.
If you are using macOS and have screen sharing enabled, Payara Server will fail to start due to screen sharing using port 5900, the same as the default Hazelcast port.You can disable macOS screen sharing in Preferences → Sharing, Disable "Screen Sharing"`, or change the Hazelcast start port. |
Disabling the Data Grid via the Admin Console
From the Admin Console homepage:
-
Select Data Grid under the instance’s configuration from the page tree:
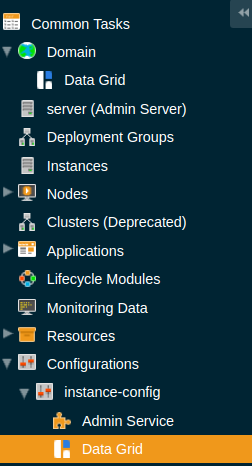
-
Un-check the Enabled option (and optionally check the Dynamic option to apply the configuration without the need for a restart) and save.
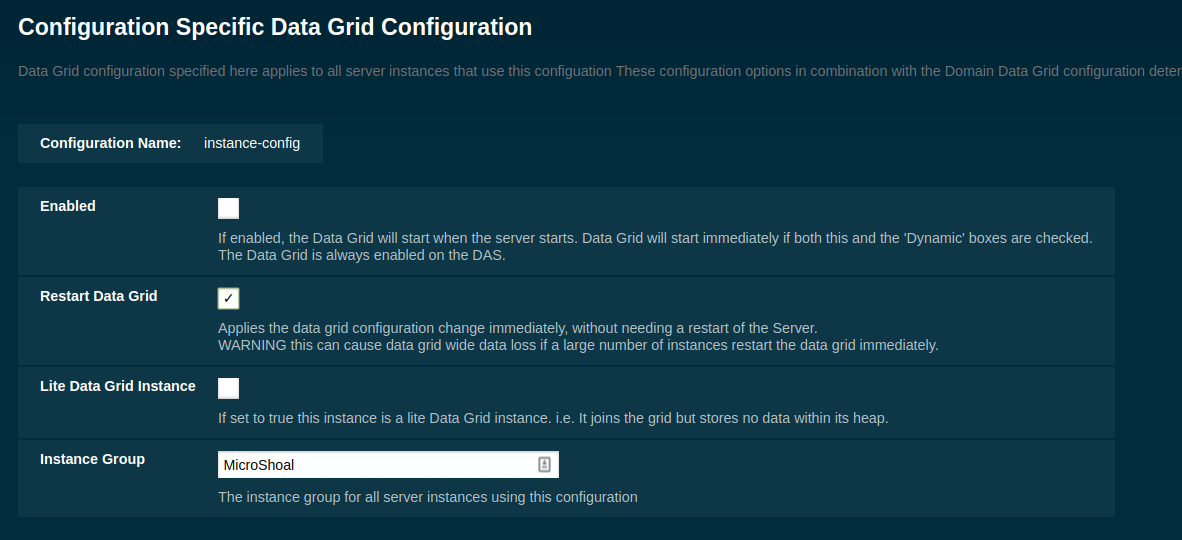
|
Disabling the Data Grid in a configuration object will disable the Data Grid for all instances using that same configuration. If this change is applied dynamically and multiple instances are restarted, there is big risk in incurring on data loss. If this is a problem, ensure not to select the dynamic option and restart each affected instance manually in turn. |
Disabling DataGrid using Asadmin CLI
The set-hazelcast-configuration asadmin command can be used to enable or disable Hazelcast and therefore the Data Grid.
This command is also used to configure other aspects of Hazelcast, which is covered in this same section. The command requires the Admin Server to be running, and will expect it to be listening on port 4848 unless specified differently with the asadmin utility --port option.
asadmin> set-hazelcast-configuration --enabled=falseIf no target is specified, the command will disable Hazelcast on the domain configuration (server-config) which equates to the DAS. To disable Hazelcast on another instance, configuration or cluster, use the --target option like so:
asadmin> set-hazelcast-configuration --enabled=false --target=${Target}The dynamic option of the asadmin command defaults to true, so to enable Hazelcast and require a restart of the target instance/cluster, use --dynamic=false:
| Same as above, dynamic restarting of multiple instances can incur in data loss, so keep this in mind. |
asadmin> set-hazelcast-configuration --enabled=false --dynamic=falseDomain Data Grid’s Hazelcast settings
Payara Server supports configuring Hazelcast through the Admin Console and asadmin commands. The Hazelcast configuration file can also be directly edited, but will not be covered in depth in this section.
Configuration of Hazelcast is divided into four sections. The first section applies to the whole domain, the second section applies to specific configurations and therefore to Payara Server instances that use that configuration, the third section covers how certain settings can be specified when a domain is created and the final section covers how to configure config specific Data Grid Start Port during or after the creation of an instance.
Using a Hazelcast configuration file will cause the settings set via the Admin Console and asadmin commands to be ignored. Any parameters not specified in the configuration file reverting to the Hazelcast defaults, even if they are specified in the Admin Console or domain.xml
| The Hazelcast defaults settings are not necessarily the same as the Payara Server’s Hazelcast default settings). |
|
The Payara Platform uses its own serializer instead of the default Hazelcast one. Setting a global serializer will not override it. This is by design, implemented to avoid a bug that causes ClassNotFoundException issues.
|
The following topics are addressed here:
Setting a custom Hazelcast Configuration File
A custom Hazelcast configuration file can be either set using Admin Console or asadmin CLI.
Setting a Hazelcast Configuration File with the Admin Console
To set the Hazelcast configuration from a Hazelcast Configuration file:
-
Select the domain Data Grid configuration from the page tree and click the Configuration tab to view the "Hazelcast Configuration" page:
-
On the Hazelcast Configuration page, add the path to your Hazelcast configuration file and click "Save". This path is relative to your domain configuration directory:
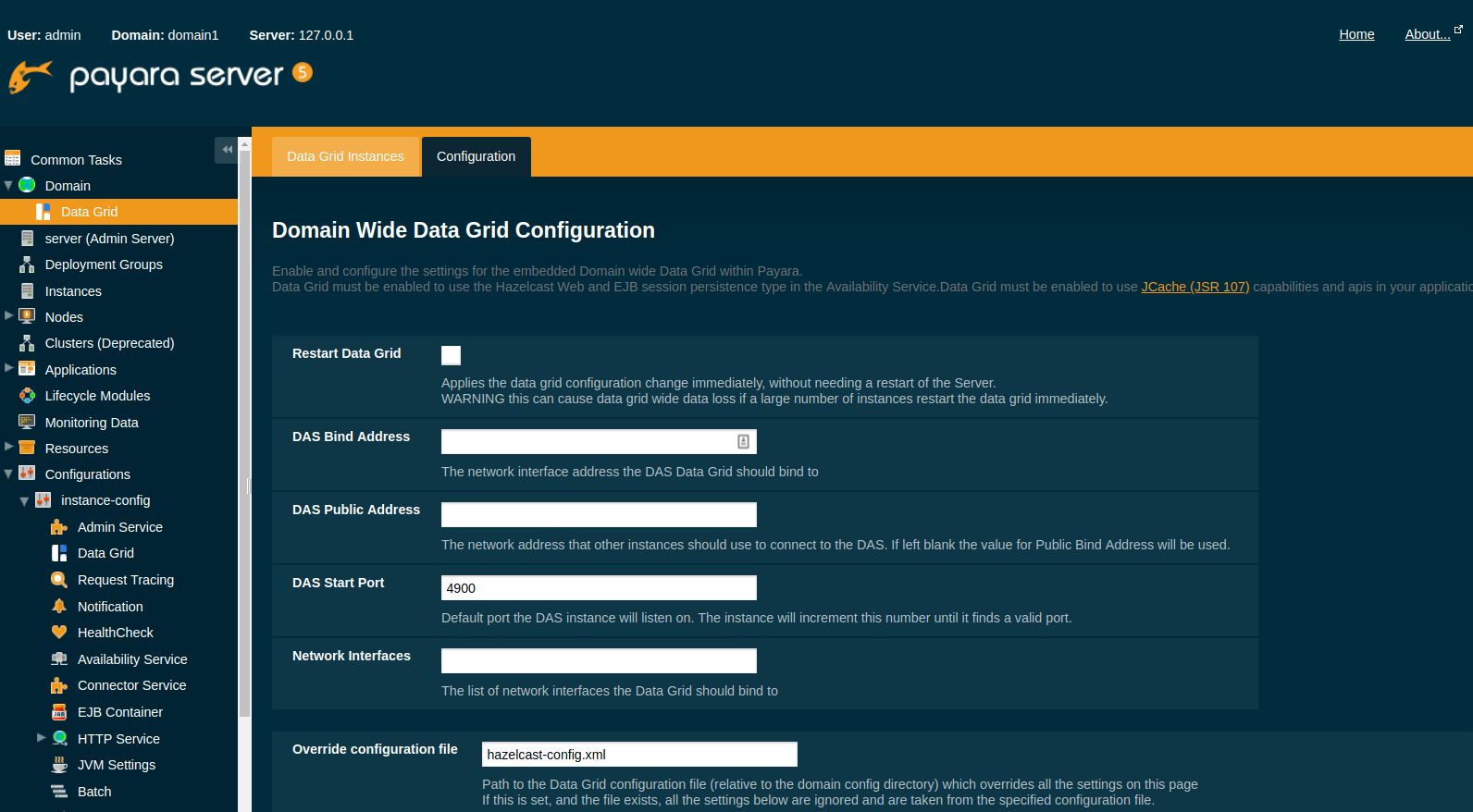
Setting a Hazelcast Configuration File using asadmin
The set-hazelcast-configuration command can be used to set the configuration file:
asadmin> set-hazelcast-configuration --hazelcastconfigurationfile /path/to/file| Payara Server currently supports a custom configuration file in either XML or YAML format. |
As with the admin console, this path is relative to your domain configuration directory.
Configuring Domain Wide Hazelcast Settings with the Admin Console
Some Hazelcast configuration settings apply to the whole domain. Navigate to the Data Grid page for the domain wide settings:
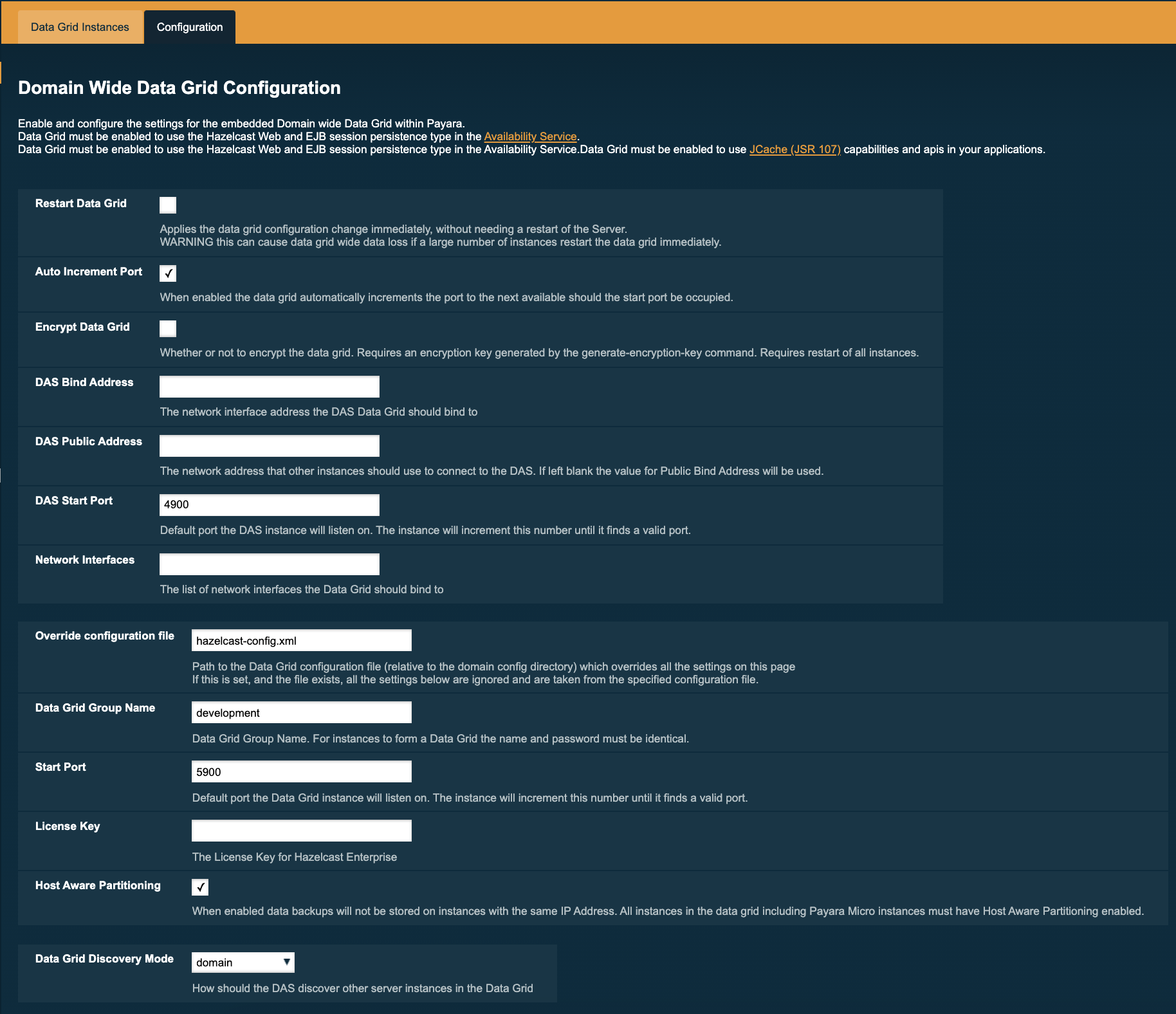
The following configuration options are available here:
| Property | Description |
|---|---|
Restart Data Grid |
Determines if the Hazelcast member embedded in Payara will be restarted to apply any changes made |
DAS Bind Address |
Explicitly specifies the IP Address the DAS should bind the Hazelcast instance to. By default, Hazelcast will try to choose the correct bind address from the IP addresses available on the host. If you find the DAS is binding to an incorrect IP Address the correct address can be specified here. |
DAS Public Address |
This is the public IP Address that the DAS should use if the DAS is behind a NAT firewall and other Payara Server Instances need to connect via the public NAT address rather than the internal IP Address |
Auto Increment Port |
By default, the cluster uses the next unoccupied port that is available starting with the start port. When auto-increment is turned off an occupied start port results in a startup failure instead. |
DAS Start Port |
The port the DAS uses to run Hazelcast on. If this port is busy, the port specified will be incremented until a valid port is found. |
Network Interfaces |
Similar to DAS Bind address by default Hazelcast will choose the correct IP Address to bind to. If you find Hazelcast is binding to the incorrect address a comma separated list of IP Addresses can be specified here. |
Override Configuration File |
Specifies the Hazelcast configuration file to use. The path specified is relative to the domain config directory.
If you are using a custom configuration for a cluster or standalone instance (e.g. cluster-config), then the Hazelcast configuration file should be placed in the directory with the same name (e.g. |
Data Grid Group Name |
Specifies the Hazelcast group name, to be optionally used to help divide clusters into logical, segregated groups (i.e. dev-group, prod-group). |
Start Port |
The port the other Payara Server instances use to run Hazelcast on. If this port is busy, the port specified will be incremented until a valid port is found. |
License Key |
Enables Hazelcast Enterprise features. |
Host Aware Partitioning |
Whether to enable host-aware partitioning for the cluster. Host aware partitioning must be enabled on all members of the cluster (including Payara Micro instances) for this feature to work correctly. This is default in Payara Server 5.181 onwards for both Payara Server domains and Payara Micro instances. |
Data Grid Discovery Mode |
See Discovery Modes |
Configuring Server Config Specific Hazelcast Settings with the Admin Console
Navigate to the Data Grid page for the specific configuration.
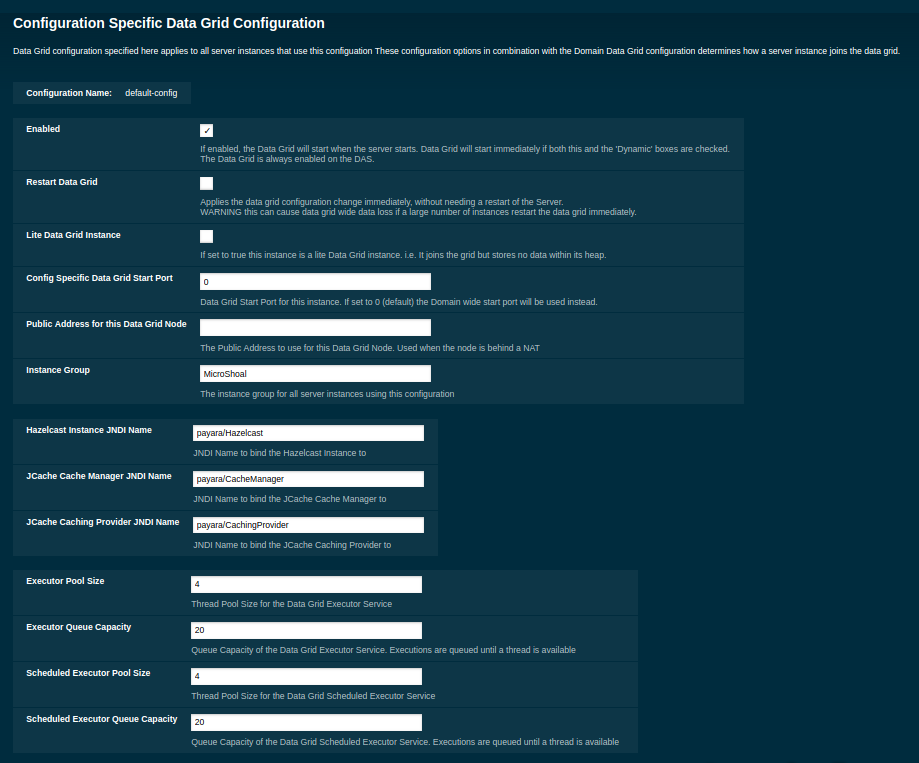
The following configuration options are available here:
| Property | Description |
|---|---|
Enabled |
See Disabling Data Grid for detailed information |
Restart Data Grid |
Determines if the Hazelcast member embedded in Payara will be restarted to apply any changes made |
Lite Data Grid Instance |
If set to true, cluster members with this configuration will be Hazelcast "lite" nodes, meaning they will not store any cache data locally and rely on other cluster members to store data. |
Config Specific Data Grid Start Port |
Sets Data Grid Start Port to the instance. If set to 0 (default) the Domain wide start port will be used instead. |
Public Address for this Data Grid Node |
The Public Address to use for this Data Grid Node. Used when the node is behind a NAT |
Instance Group |
Instance group name for all Server Instances using the configuration. Future functionality may use this name. |
Hazelcast Instance JNDI Name |
The JNDI name to bind the Hazelcast instance to. |
JCache Manager JNDI Name |
The JNDI name to bind the JCache Cache Manager to. |
JCache Caching Provider JNDI Name |
The JNDI name to bind the JCache Caching Provider to. |
Executor Pool Size |
The thread pool’s size for the Hazelcast Executor service |
Executor Queue Capacity |
Queue Capacity of the Data Grid Executor Service. Executions are queued until a thread is available |
Scheduled Executor Pool Size |
The thread pool’s size for the Hazelcast Scheduled Executor service |
Scheduled Executor Queue Capacity |
Queue Capacity of the Data Grid Scheduled Executor Service. Executions are queued until a thread is available |
Enter your required values, and click Save. Restarting the domain or instance/cluster is not necessary for any changes made to take effect, provided that "Dynamic" remains set to true
Configuring Hazelcast on Domain Creation
The following options can be used with the create-domain command to specify certain Hazelcast settings when a domain is created. An example of create-domain command with Hazelcast specific options:
asadmin> create-domain --hazelcastdasport 7900 --hazelcaststartport 8900 --hazelcastautoincrement true testDomainConfiguring Config Specific Data Grid Start Port for an Instance
It is possible to configure the port used by Hazelcast to bind the corresponding instance to the Data Grid by letting users set its value during or after the creation of an instance.
Configuring Config Specific Data Grid Start Port on Instance Creation
The --dataGridStartPort option can be used with the create-instance or the create-local-instance commands to specify config Specific Data Grid Start Port when an instance is created.
Configuring Data Grid Start Port After Instance Creation
You can configure the start port used by an instance after its creation by either using the Admin Console or the asadmin CLI.
Setting Data Grid Start Port with the Admin Console
-
Select the Configuration from the page tree, click on the relevant instance and finally click on the Data Grid.
-
On the Configuration Specific Data Grid Configuration, set the Data Grid Start Port and click Save.
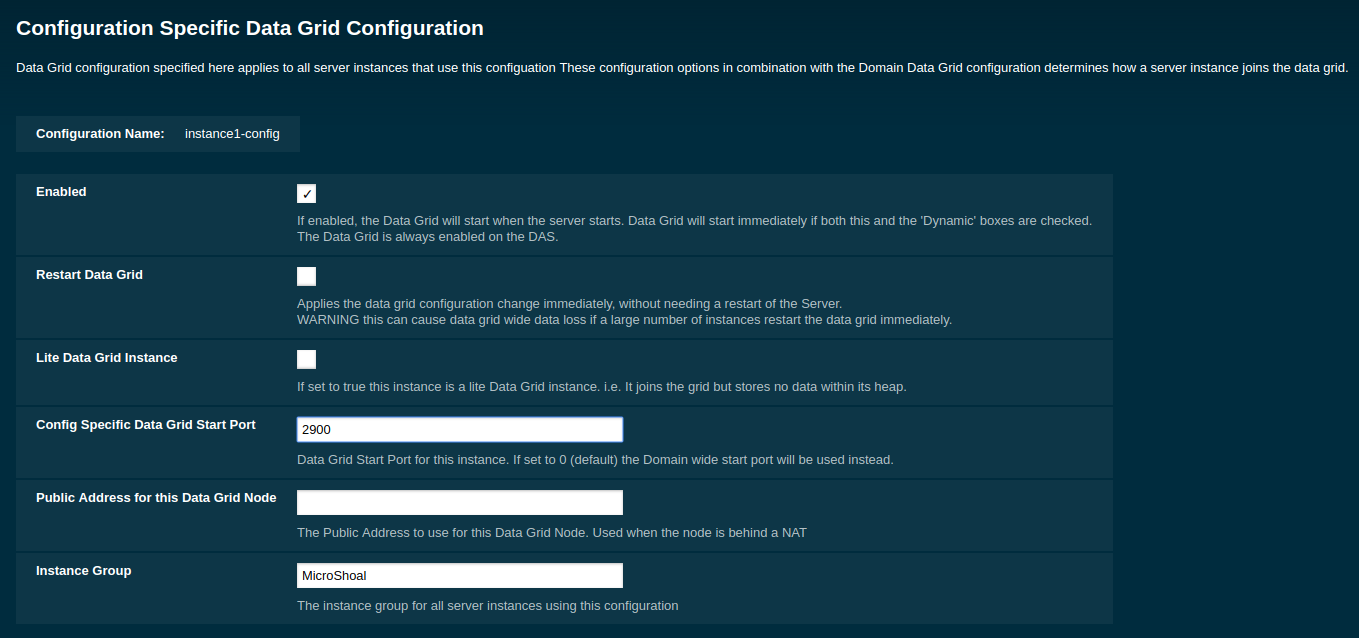
Setting Data Grid Start Port using asadmin CLI
The set-hazelcast-configuration command can be used to set the Data Grid start port:
asadmin> set-hazelcast-configuration --dynamic=true --configSpecificDataGridStartPort=2900 --target=instance1-configConfiguring the Hazelcast CP Subsystem
The CP Subsystem is a component of a Hazelcast cluster that builds a strongly consistent layer for a set of distributed data structures. The CP Subsystem withstands server and client failures and offer special features to Payara Server applications.
You can read more about the CP subsystem in the official Hazelcast Platform documentation.
To enable the CP subsystem, you will have to configure the hazelcast.cp-subsystem.cp-member-count system property to a value greater than zero (read the recommendations in the Hazelcast Platform documentation to pick a suitable member count). Hazelcast recommends that a minimum of 3 members need to be configured for the CP subsystem to work as intended.
Additionally, the hazelcast.cp-subsystem.auto-promote Payara Platform system property can be used to configure an auto-promote behaviour that will allow other server instances to join the CP subsystem when detected by the DAS.
| The CP subsystem is not actively tested as a recommended feature of Payara Server and should be used with extreme caution on highly dynamic environments. |
Viewing Data Grid Members
This section details how to visualize the members of the Domain Data Grid in Payara Server.
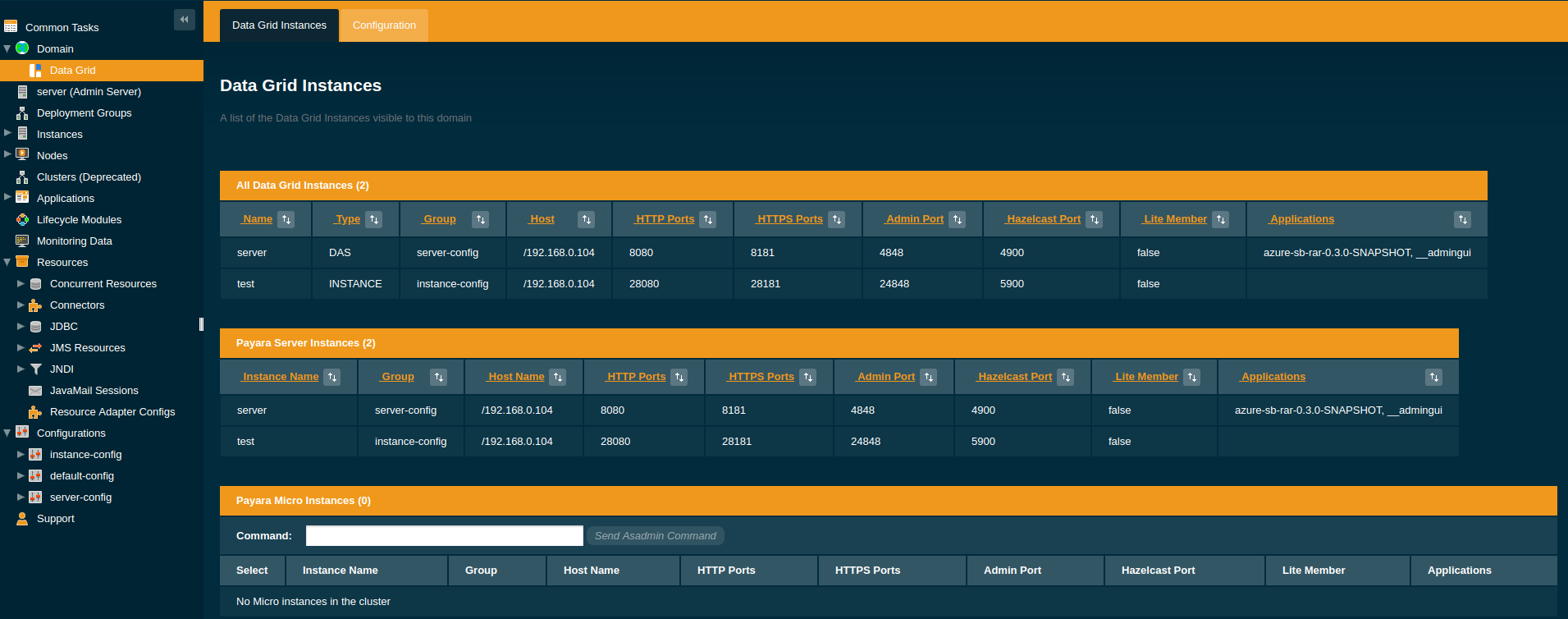
Viewing Cluster Members via asadmin
To view the current cluster members from the command line, run either the list-hazelcast-members or the list-hazelcast-cluster-members asadmin commands:
asadmin> list-hazelcast-members
\{ server-MicroShoal-/192.168.1.148:4900-this \}asadmin> list-hazelcast-cluster-members
Instance Name Instance Group Instance Type Host Name HTTP Ports HTTPS Ports Admin Port Hazelcast Port Lite Member Deployed Applications Last Hearbeat
server server-config DAS 127.0.1.1 8080 8181 4848 5900 false __admingui 2019-03-05 09:25:42| The Last Heartbeat attribute will display the date and time that the DAS last received a heartbeat pulse from a Payara Server or Payara Micro instance. This heartbeat should refresh every 5 seconds. |
Data Grid Encryption
Encryption of the data stored within the data grid of Hazelcast has previously required a Hazelcast Enterprise subscription. While this remains an option for those who would like the additional features it provides (such as WAN replication), Payara Server now includes its own encryption implementation that provides this feature to you without an additional subscription.
The following topics are addressed here:
Encryption Mechanism
This feature provides encryption of the data that’s being stored in-memory via the Hazelcast data grid, providing end-to-end encryption of the data across all instances in the domain. End-to-end encryption is encryption of data both at rest (in storage) and in transit (during communication).
Payara Server uses a symmetric key to perform the encryption of the data within the data grid store. This means that the same key is used by each member of the data grid to encrypt and decrypt the data.
This key is generated and protected using the master password and a key derivation function. The key itself is a 256-bit AES key, utilising an initialisation vector and a salt for each call of encryption to help prevent any statistical pattern recognition.
Encryption Targets
The following data stores are encrypted:
-
Web Session Persistence
-
Stateful Session Bean Persistence
-
Request Traces
-
Historic Health Checks
Setup
This section details the necessary steps to set up and enable encryption of the data grid and the various data stores.
Documentation around configuration of the data sources for encryption assumes that you’ve already generated the encryption key and enabled encryption of the data grid.
Generating an Encryption Key
The key to be used by Payara Server to perform the actual encryption and decryption of data can be generated using the generate-encryption-key asadmin command:
asadmin> generate-encryption-keyThis command generates a key using the master password – the same one used to access the key store used by Payara Server. Similar to the change-master-password command, this command requires you to shut down the DAS first.
| This command should only be run on the DAS since this is the master instance, and will be the instance propagating the key out to other instances in the domain. |
The default value for the master password is changeit. You can also provide the master password via a password file like so:
asadmin> -W /path/to/passwordfile.txt generate-encryption-keyThat will generate a new file with the following contents:
AS_ADMIN_MASTERPASSWORD=changeit
If you change the master password after generating your key, you’ll need to regenerate and propagate the new key to each of your instances since the original key was created using the old (and now incorrect) password. This should occur under the default --sync normal, but --sync full can be used to delete the local copy and resynchronize it.
|
Enabling Encryption in Hazelcast
Enabling encryption of the data grid itself is controlled by the set-hazelcast-configuration asadmin command, with the --encryptdatagrid parameter:
asadmin> set-hazelcast-configuration --encryptdatagrid trueThis is a domain-wide setting, and thus means that hybrid setups where encryption is enabled only on specific clusters within a domain is not supported.
|
Once you’ve generated your key and enabled encryption, you must restart all instances in the domain if they were still running; changes in encryption settings do not take effect until a server is restarted. It is highly recommended that you restart all of your running instances as quickly as possible, since those that haven’t been restarted will be unable to decrypt the encrypted data placed in the data grid store by those that have been. |
Web Session Availability Configuration
Encrypting web session availability data requires no extra actions on top of configuring the Web Container Availability Persistence Type to hazelcast (which it is by default).
asadmin> set configs.config.server-config.availability-service.web-container-availability.persistence-type=hazelcastStateful Session Bean Configuration
Encrypting Stateful Session Beans (SFSB) availability data requires no extra actions on top of configuring the EJB Container Availability HA and/or SFSB Persistence Type to hazelcast:
asadmin> set configs.config.server-config.availability-service.ejb-container-availability.sfsb-ha-persistence-type=hazelcast
asadmin> set configs.config.server-config.availability-service.ejb-container-availability.sfsb-persistence-type=hazelcastThe Hazelcast PhoneHome Service
In a similar manner to the server’s Phone Home service, Hazelcast Community Edition also comes with an internal service that makes all instances that belong to the DataGrid send phone data regularly.
As with the Platform’s phone home service, if you want to disable Hazelcast Phone Home service, it can be done via either the HZ_PHONE_HOME_ENABLED environment variable (set it to false) or by using the hazelcast.phone.home.enabled system property:
asadmin create-jvm-options --target server-config "-Dhazelcast.phone.home.enabled=false"